Les meilleures technologies Big Data que vous devez connaître
Les technologies Big Data, Le mot à la mode que vous entendez beaucoup ces derniers jours. Dans cet article, Nous discuterons des technologies révolutionnaires qui ont permis au Big Data de diffuser ses branches pour atteindre de plus grands sommets.
- Qu’est-ce que la technologie du Big Data ?
- Types de Technologie Big Data
- Top Technologies Big Data
- Technologies Big Data émergentes
Qu’est-ce que la Technologie Big Data?
La technologie Big Data peut être définie comme un Utilitaire Logiciel conçu pour Analyser, Traiter et Extraire les informations d’un ensemble de données extrêmement complexe et volumineux que les Logiciels de traitement de Données traditionnels ne pourraient jamais traiter.

Nous avons besoin de technologies de traitement des mégadonnées pour analyser cette énorme quantité de données en temps réel et formuler des conclusions et des prédictions afin de réduire les risques à l’avenir.
Examinons maintenant les catégories dans lesquelles les technologies Big Data sont classées:
Types de technologies Big Data:
La technologie Big Data est principalement classée en deux types:
- Technologies Opérationnelles du Big Data
- Technologies analytiques du Big Data

Premièrement, le Big Data opérationnel concerne les données quotidiennes normales que nous générons. Cela peut être les Transactions en ligne, les Médias sociaux ou les données d’une Organisation particulière, etc. Vous pouvez même considérer qu’il s’agit d’une sorte de Données brutes utilisées pour alimenter les technologies de Big Data Analytiques.
Quelques exemples de technologies de Big Data opérationnelles sont les suivants:
- Réservations de billets en ligne, qui comprend vos billets de train, vos billets d’avion, vos billets de cinéma, etc.
- Achats en ligne qui est votre offre Amazon, Flipkart, Walmart, Snap et bien d’autres.Facebook Instagram, what’s app et bien plus encore.
- Données provenant de sites de médias sociaux comme Facebook, Instagram, what’s app et bien plus encore.
- Les coordonnées des employés de toute entreprise multinationale.
Alors, avec cela, passons aux technologies de Big Data Analytiques.
Le Big Data analytique est comme la version avancée des technologies Big Data. C’est un peu plus complexe que le Big Data opérationnel. En bref, le big data analytique est l’endroit où la partie réelle de la performance entre en jeu et où les décisions commerciales cruciales en temps réel sont prises en analysant le Big Data opérationnel.
Quelques exemples de technologies analytiques Big Data sont les suivants:

- Stock marketing
- Réalisation des missions spatiales où chaque information est cruciale.
- Informations sur les prévisions météorologiques.
- Domaines médicaux où l’état de santé d’un patient particulier peut être surveillé.
Jetons un coup d’œil aux principales technologies de Big Data utilisées dans les industries informatiques.
Top Big Data Technologies
Les Top Big Data technologies sont divisées en 4 champs qui sont classés comme suit:
- Stockage de données
- Exploration de données
- Analyse de données
- Visualisation de données
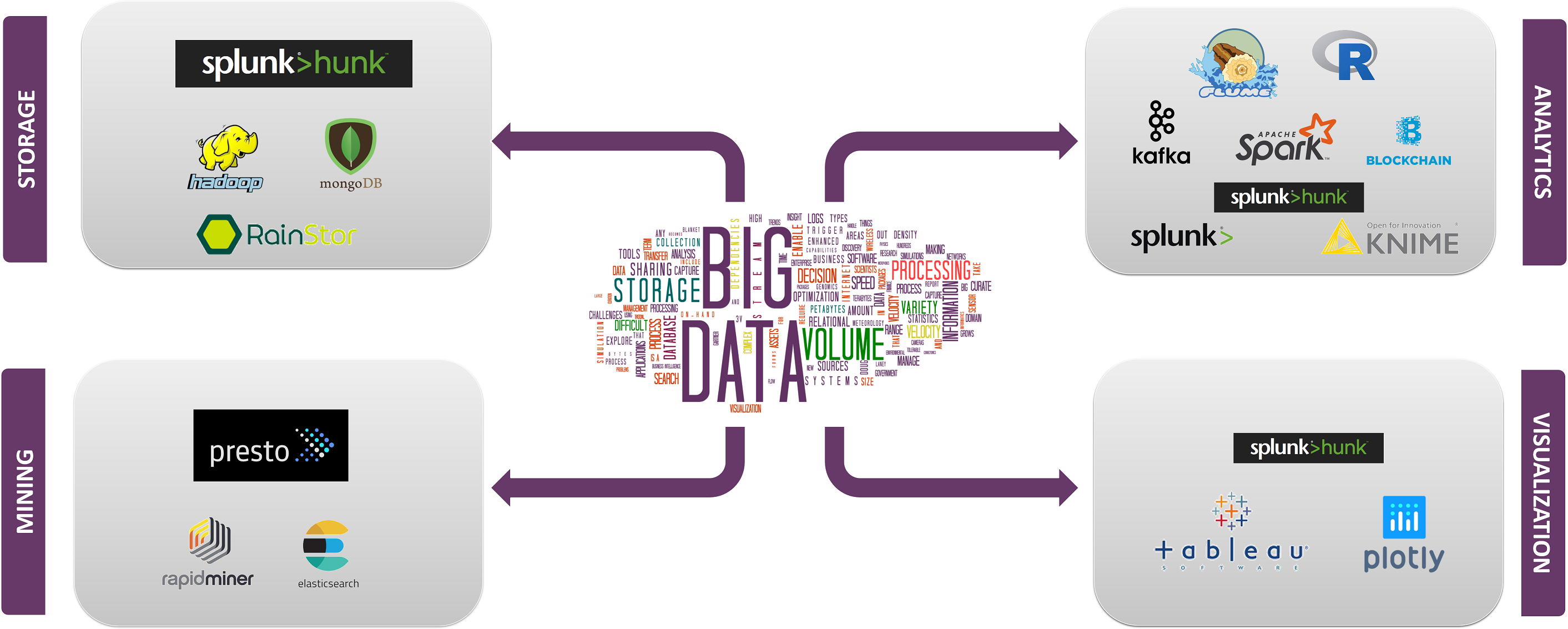
Abordons maintenant les technologies relevant de chacune de ces catégories avec leurs faits et capacités, ainsi que les entreprises qui les utilisent.
Commençons avec les technologies Big Data dans le stockage de données.
Stockage de données
Hadoop
![]()
Le framework Hadoop a été conçu pour stocker et traiter des données dans un Environnement de traitement de données distribué avec du matériel de base avec un modèle de programmation simple. Il peut Stocker et Analyser les données présentes dans différentes machines à des Vitesses élevées et à Faible coût.
-
-
-
-
- Développé par: Apache Software Foundation en l’an 2011 10 décembre.
- Écrit en: JAVA
- Version stable actuelle: Hadoop 3.11
-
-
-
Entreprises Utilisant Hadoop:
MongoDB

Les bases de données de documents NoSQL comme MongoDB, offrent une alternative directe au schéma rigide utilisé dans les bases de données relationnelles. Cela permet à MongoDB d’offrir de la flexibilité tout en gérant une grande variété de types de données à de grands volumes et sur des architectures distribuées.
-
-
-
-
- Développé par: MongoDB en l’an 2009 11 février
- Écrit en: C++, Go, JavaScript, Python
- Version stable actuelle : MongoDB 4.0.10
-
-
-
Entreprises Utilisant MongoDB:

Rainstor
![]() RainStor est une société de logiciels qui a développé un système de gestion de base de données du même nom conçu pour Gérer et analyser les Big Data pour les grandes entreprises. Il utilise des techniques de déduplication pour organiser le processus de stockage de grandes quantités de données pour référence.
RainStor est une société de logiciels qui a développé un système de gestion de base de données du même nom conçu pour Gérer et analyser les Big Data pour les grandes entreprises. Il utilise des techniques de déduplication pour organiser le processus de stockage de grandes quantités de données pour référence.
-
-
-
-
- Développé par: RainStor Software company en 2004.
- Fonctionne comme: SQL
- Version stable actuelle: RainStor 5.5
-
-
-
Entreprises Utilisant RainStor:

Beau Gosse

Hunk vous permet d’accéder aux données des clusters Hadoop distants via des index virtuels et d’utiliser le langage de traitement de recherche Splunk pour analyser vos données. Avec Hunk, vous pouvez générer des rapports et visualiser de grandes quantités à partir de vos sources de données Hadoop et NoSQL.
-
-
-
-
- Développé par: Splunk INC en 2013.
- Écrit en: JAVA
- Version stable actuelle: Splunk Hunk 6.2
-
-
-
Passons maintenant aux technologies Big Data utilisées dans l’exploration de données.
Exploration de données
Presto

Presto est un moteur de requête SQL Distribué Open source permettant d’exécuter des Requêtes Analytiques Interactives sur des sources de données de toutes tailles allant du Gigaoctet au Pétaoctet. Presto permet d’interroger des données dans Hive, Cassandra, des bases de données Relationnelles et des magasins de données propriétaires.
-
-
-
-
- Développé par: Fondation Apache en 2013.
- Écrit en: JAVA
- Version stable actuelle: Presto 0.22
-
-
-
Entreprises utilisant Presto:

Rapid Miner
![]()
RapidMiner est une solution centralisée dotée d’une interface utilisateur graphique très puissante et robuste qui permet aux utilisateurs de Créer, de fournir et de maintenir des analyses prédictives. Il permet de créer des flux de travail très avancés, de prendre en charge les scripts en plusieurs langues.
-
-
-
-
- Développé par: RapidMiner en 2001
- Écrit en : JAVA
- Version stable actuelle: RapidMiner 9.2
-
-
-
Entreprises utilisant RapidMiner:

Elasticsearch
![]()
Elasticsearch est un moteur de recherche basé sur la Bibliothèque Lucene. Il fournit un Moteur de recherche en texte intégral Distribué, compatible avec plusieurs clients, avec une interface Web HTTP et des documents JSON sans schéma.
-
-
-
-
- Développé par: Elastic NV en 2012.
- Écrit en: JAVA
- Version stable actuelle : ElasticSearch 7.1
-
-
-
Entreprises Utilisant Elasticsearch:

Avec cela, nous pouvons maintenant passer aux technologies Big Data utilisées dans l’analyse de données.
Analyse de données
Kafka

Apache Kafka est une plateforme de streaming distribuée. Une plate-forme de streaming a trois capacités clés qui sont les suivantes:
-
-
-
-
- Editeur
- Abonné
- Consommateur
-
-
-
Ceci est similaire à une file d’attente de messages ou à un système de messagerie d’entreprise.
- Développé par: Apache Software Foundation en 2011
- Écrit en: Scala, JAVA
- Version stable actuelle: Apache Kafka 2.2.0
Entreprises Utilisant Kafka:

Splunk
 Splunk capture, Indexe et corrèle des données en temps réel dans un Référentiel interrogeable à partir duquel il peut générer des Graphiques, des Rapports, des Alertes, des Tableaux de bord et des Visualisations de données. Il est également utilisé pour la Gestion des applications, la Sécurité et la Conformité, ainsi que pour l’Analyse commerciale et Web.
Splunk capture, Indexe et corrèle des données en temps réel dans un Référentiel interrogeable à partir duquel il peut générer des Graphiques, des Rapports, des Alertes, des Tableaux de bord et des Visualisations de données. Il est également utilisé pour la Gestion des applications, la Sécurité et la Conformité, ainsi que pour l’Analyse commerciale et Web.
-
-
-
-
- Développé par: Splunk INC au cours de l’année 2014 6 mai
- Écrit en: AJAX, C++, Python, XML
- Version stable actuelle: Splunk 7.3
-
-
-
Entreprises Utilisant Splunk:

KNIME
 KNIME permet aux utilisateurs de créer visuellement des flux de données, d’exécuter sélectivement certaines ou Toutes les étapes d’analyse et d’Inspecter les Résultats, les Modèles et les vues interactives. KNIME est écrit en Java et basé sur Eclipse et utilise son mécanisme d’extension pour ajouter des Plugins fournissant des Fonctionnalités supplémentaires.
KNIME permet aux utilisateurs de créer visuellement des flux de données, d’exécuter sélectivement certaines ou Toutes les étapes d’analyse et d’Inspecter les Résultats, les Modèles et les vues interactives. KNIME est écrit en Java et basé sur Eclipse et utilise son mécanisme d’extension pour ajouter des Plugins fournissant des Fonctionnalités supplémentaires.
-
-
-
-
- Développé par: KNIME en l’an 2008
- Écrit en: JAVA
- Version stable actuelle : KNIME 3.7.2
-
-
-
Entreprises Utilisant KNIME:
 Spark
Spark

Spark fournit des capacités de calcul en mémoire pour fournir de la vitesse, un modèle d’exécution généralisé pour prendre en charge une grande variété d’applications et des API Java, Scala et Python pour faciliter le développement.
-
-
-
-
- Développé par : Apache Software Foundation
- Écrit en: Java, Scala, Python, R
- Version stable actuelle: Apache Spark 2.4.3
-
-
-
Entreprises Utilisant Spark:

Langue R

R est un langage de programmation et un environnement logiciel libre pour le Calcul statistique et Graphique. Le langage R est largement utilisé par les Statisticiens et les Mineurs de Données pour le développement de Logiciels Statistiques et principalement dans l’Analyse de Données.
-
-
-
-
- Développé par: R-Foundation en l’an 2000 29 février
- Écrit en: Fortran
- Version stable actuelle: R-3.6.0
-
-
-
Entreprises Utilisant Le Langage R:

Blockchain
![]() La BlockChain est utilisée dans des fonctions essentielles telles que le paiement, l’entiercement et le titre peut également réduire la fraude, augmenter la confidentialité financière, accélérer les transactions et internationaliser les marchés.
La BlockChain est utilisée dans des fonctions essentielles telles que le paiement, l’entiercement et le titre peut également réduire la fraude, augmenter la confidentialité financière, accélérer les transactions et internationaliser les marchés.
La BlockChain peut être utilisée pour réaliser ce qui suit dans un environnement de réseau d’entreprise:
-
-
-
-
- Grand Livre Partagé: Ici, nous pouvons ajouter le Système distribué d’enregistrements sur un réseau d’entreprise.
- Contrat intelligent : Les termes commerciaux sont intégrés dans la base de données de transactions et exécutés avec les transactions.
- Confidentialité : Assurer une visibilité appropriée, Les transactions sont sécurisées, Authentifiées et vérifiables
- Consensus : Toutes les parties d’un réseau d’entreprise acceptent les transactions vérifiées par le réseau.
-
-
-
- Développé par: Bitcoin
- Écrit en: JavaScript, C++, Python
- Version stable actuelle: Blockchain 4.0
Entreprises Utilisant La Blockchain:

Avec cela, nous passerons à la visualisation de données Technologies Big Data
Visualisation de données
Tableau

Tableau est un outil de visualisation de données puissant et à la croissance la plus rapide utilisé dans le secteur de la Business Intelligence. L’analyse des données est très rapide avec Tableau et les Visualisations créées se présentent sous forme de Tableaux de bord et de feuilles de calcul.
-
-
-
-
- Développé par : TableAU 2013 17 mai
- Écrit en: JAVA, C++, Python, C
- Version stable actuelle : TableAU 8.2
-
-
-
Entreprises Utilisant Tableau:

Plotly
![]()
Principalement utilisé pour rendre la création de graphiques plus rapide et plus efficace. Bibliothèques d’API pour Python, R, MATLAB, Node.js, Julia et Arduino et une API REST. Plotly peut également être utilisé pour styliser des graphiques interactifs avec Jupyter notebook.
-
-
-
-
- Développé par: Plotly dans l’année 2012
- Écrit en: JavaScript
- Version stable actuelle: Plotly 1.47.4
-
-
-
Entreprises Utilisant Plotly:
 parlons maintenant des technologies émergentes du Big Data
parlons maintenant des technologies émergentes du Big Data
Technologies émergentes du Big Data
TensorFlow

TensorFlow dispose d’un écosystème complet et flexible d’outils, de bibliothèques et de ressources communautaires qui permet aux chercheurs de développer l’état de l’art en apprentissage automatique et aux développeurs de créer et de déployer facilement des applications alimentées par l’apprentissage automatique.
-
-
-
-
- Développé par: Google Brain Team au cours de l’année 2019
- Écrit en: Python, C++, CUDA
- Version stable actuelle: TensorFlow 2.0 beta
-
-
-
Entreprises Utilisant TensorFlow:

Faisceau
![]()
Apache Beam fournit une couche d’API portable pour la création de pipelines sophistiqués de traitement de données parallèles pouvant être exécutés sur une variété de Moteurs d’exécution ou de Runners.
-
-
-
-
- Développé par: Fondation du logiciel Apache dans l’année 2016 15 juin
- Écrit en: JAVA, Python
- Version stable actuelle: Apache Beam 0.1.0 incubation.
-
-
-
Entreprises Utilisant Beam:
 Docker
Docker

Docker est un outil conçu pour faciliter la création, le déploiement et l’exécution d’applications à l’aide de conteneurs. Les conteneurs permettent à un développeur d’empaqueter une application avec toutes les pièces dont il a besoin, telles que les bibliothèques et autres dépendances, et de l’expédier en un seul paquet.
-
-
-
-
- Développé par: Docker INC au cours de l’année 2003 13 mars.
- Écrit en: Go
- Version stable actuelle: Docker 18.09
-
-
-
Entreprises utilisant Docker:

Airflow
![]() Apache Airflow est un système d’automatisation et de planification des flux de travail qui peut être utilisé pour créer et gérer des pipelines de données. Airflow utilise des flux de travail constitués de graphiques acycliques dirigés (DAG) de tâches. La définition de Workflows dans le code facilite la Maintenance, les Tests et le contrôle des versions.
Apache Airflow est un système d’automatisation et de planification des flux de travail qui peut être utilisé pour créer et gérer des pipelines de données. Airflow utilise des flux de travail constitués de graphiques acycliques dirigés (DAG) de tâches. La définition de Workflows dans le code facilite la Maintenance, les Tests et le contrôle des versions.
-
-
-
-
- Développé par : Apache Software Foundation le 15 mai 2019
- Écrit en: Python
- Version stable actuelle: Apache AirFlow 1.10.3
-
-
-
Entreprises utilisant AirFlow:

Kubernetes
 Kubernetes est un outil de gestion de clusters et de conteneurs indépendant des fournisseurs, Open Source par Google en 2014. Il fournit une plate-forme pour l’automatisation, le Déploiement, la mise à l’échelle et les opérations des Conteneurs d’applications sur des clusters d’hôtes.
Kubernetes est un outil de gestion de clusters et de conteneurs indépendant des fournisseurs, Open Source par Google en 2014. Il fournit une plate-forme pour l’automatisation, le Déploiement, la mise à l’échelle et les opérations des Conteneurs d’applications sur des clusters d’hôtes.
-
-
-
-
- Développé par: Cloud Native Computing Foundation en 2015 21 juillet
- Écrit en: Go
- Version stable actuelle: Kubernetes 1.14
-
-
-
Entreprises Utilisant Kubernetes:

Avec cela, nous arrivons à la fin de cet article. J’espère avoir mis en lumière vos connaissances sur le Big Data et ses technologies.
Maintenant que vous avez compris le Big data et ses technologies, consultez la formation Hadoop d’Edureka, une entreprise d’apprentissage en ligne de confiance avec un réseau de plus de 250 000 apprenants satisfaits répartis dans le monde entier. La formation de certification Edureka Big Data Hadoop aide les apprenants à devenir experts en HDFS, Yarn, MapReduce, Pig, Hive, HBase, Oozie, Flume et Sqoop en utilisant des cas d’utilisation en temps réel sur le domaine de la vente au détail, des Médias sociaux, de l’Aviation, du Tourisme et de la Finance.