Aggregate() függvény az R-ben
az R-ben lévő Aggregate() függvény részhalmazokra bontja az adatokat, kiszámítja az egyes részhalmazok összefoglaló statisztikáit, és az eredményt űrlap szerint csoportosítva adja vissza. Az R összesített függvénye hasonló a group by in SQL-hez. Az Aggregate() függvény hasznos az összes aggregált művelet végrehajtásában,mint például a sum,count, mean, minimum és Maximum.
lássunk egy példát a következő
- Aggregate (), amely kiszámítja csoport összege
- számítsuk ki a csoport max és minimum segítségével aggregate() függvény
- Aggregate() függvény, amely kiszámítja csoport átlag
- Get csoport számít segítségével aggregate() funkció
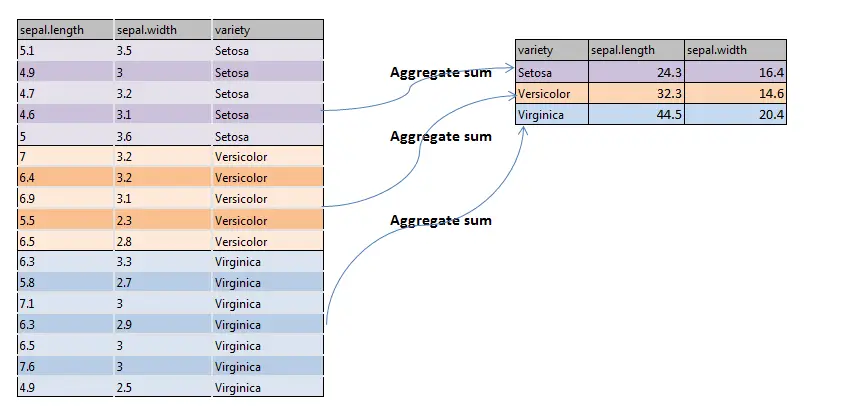
a az aggregált() függvény piktográfiai ábrázolása, azaz az aggregált összeg az alábbiakban látható
szintaxis Aggregate () függvény R:
| X | r objektum, többnyire adatkeret |
| by | csoportosítási elemek listája, amelyek szerint a részhalmazok csoportosítva vannak |
| FUN | függvény az összefoglaló statisztikák kiszámításához |
| egyszerűsítés | logikai jelzés, hogy az eredményeket egyszerűsíteni kell-e vektorra vagy mátrixra, ha lehetséges |
| csepp | logikai jelzi, hogy dobja fel nem használt kombinációi csoportosítás értékeket. |
példa az Aggregate () függvényre R – ben:
használjuk az iris adatkészletet az aggregate függvény egyszerű példájának bemutatására R-ben. Tegyük fel, hogy meg akarja találni az összes mutató átlagát (Sepal.Hossza Sepal.Szélesség Szirom.Hossza Szirom.
# Aggregate function in R with mean summary statisticsagg_mean = aggregate(iris,by=list(iris$Species),FUN=mean, na.rm=TRUE)agg_mean
a fenti kód az írisz adatkészletének első 4 oszlopát veszi fel, és “fajok” szerint csoportosítja az egyes csoportok átlagának kiszámításával, így a kimenet

megjegyzés: Az aggregate () függvény használatakor a by változóknak egy listában kell lenniük.
példa az aggregate() függvényre R-ben sum-mal:
használjuk az aggregate() függvényt R-ben, hogy létrehozzuk az összes mutató összegét a fajok között és a csoportok szerint.
# Aggregate function in R with sum summary statisticsagg_sum = aggregate(iris,by=list(iris$Species),FUN=sum, na.rm=TRUE)agg_sum
amikor a fenti kódot végrehajtjuk, a kimenet

példa az aggregate() függvényre R-ben count-tal:
használjuk az aggregate () függvényt, hogy létrehozzuk az összes mutató számát fajonként és csoportonként.
# Aggregate function in R with countagg_count = aggregate(iris,by=list(iris$Species),FUN=length)agg_count
a fenti kód az írisz adatkészletének első 4 oszlopát veszi fel, és “fajok” szerint csoportosítja az egyes csoportok számának kiszámításával, így a kimenet
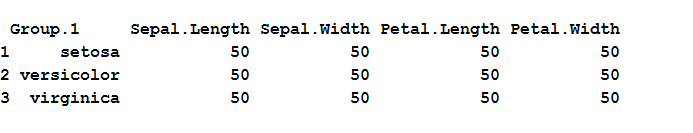
példa az aggregate() függvényre az R-ben a maximummal:
használjuk az aggregate () függvényt az összes mutató maximumának létrehozásához fajonként és csoportonként.
# Aggregate function in R with maximumagg_max = aggregate(iris,by=list(iris$Species),FUN=max, na.rm=TRUE)agg_max
a fenti kód az írisz adatkészletének első 4 oszlopát veszi fel, és “fajok” szerint csoportosítja az egyes csoportok max értékét, így a kimenet

példa az aggregate() függvényre az R-ben minimummal:
használjuk az aggregate () függvényt, hogy létrehozzuk az összes mutató minimumát fajonként és csoportonként.
# Aggregate function in R with minimumagg_min = aggregate(iris,by=list(iris$Species),FUN=min, na.rm=TRUE)agg_min
a fenti kód az írisz adatkészletének első 4 oszlopát veszi fel, és “fajok” szerint csoportosítja az egyes csoportok min-jének kiszámításával, így a kimenet
