KDnuggets
Di Sydney Firmin, Alteryx.
“Essenzialmente, tutti i modelli sono sbagliati, ma alcuni modelli sono utili.”- George Box
Questa famosa citazione di George Box fu registrata per la prima volta nel 1976 nel documento “Science and Statistics”, pubblicato nel Journal of the American Statistical Association. Si tratta di una citazione importante per il campo della statistica e modelli analitici e può essere scompattato in due parti.
Tutti i modelli sono errati
Per approfondire questa affermazione, dobbiamo definire ed esaminare cos’è un modello.
Per il contesto di questo articolo, un modello può essere pensato come una rappresentazione semplificata di un sistema o di un oggetto. I modelli statistici approssimano i modelli in un set di dati facendo ipotesi sui dati e sull’ambiente in cui sono stati raccolti e applicati.
Le tre grandi categorie di ipotesi formulate dai modelli statistici sono ipotesi distributive (ipotesi sulla distribuzione di valori in una variabile o la distribuzione di errori osservazionali), ipotesi strutturali (ipotesi sulla relazione funzionale tra variabili) e ipotesi di variazione incrociata (distribuzione di probabilità congiunta).
Ad esempio, un modello di regressione lineare presuppone che le relazioni tra le variabili in un set di dati siano lineari (e solo lineari). Agli occhi di un modello lineare, qualsiasi distanza tra le osservazioni che compongono il set di dati e la linea modellata è solo rumore (cioè fluttuazioni casuali o inspiegabili nei dati) e può essere ignorata.
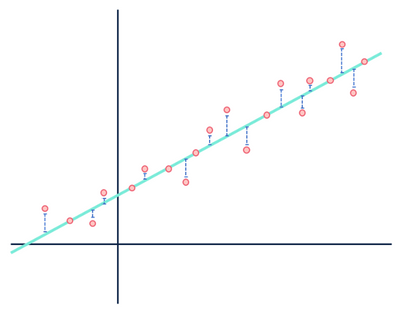
Non badare alle distanze in blu.
George Box ha dichiarato che tutti i modelli sono sbagliati specificamente nel contesto dei modelli statistici. Poiché la natura stessa di un modello è una rappresentazione semplificata e idealizzata di qualcosa, tutti i modelli saranno sbagliati in un certo senso. I modelli non saranno mai “la verità” se verità significa interamente rappresentativo della realtà. È molto importante considerare le ipotesi fatte nella generazione di un modello perché i modelli sono veramente utili solo quando le ipotesi sono trattenute.
Mappe e Miniature
Osservazioni simili a “all models are wrong” di Box sono presenti in molti campi diversi.
C’è un aforisma che fa riferimento alla relazione mappa-territorio, attribuito ad Alfred Korzybski:
Una mappa non è il territorio che rappresenta, ma, se corretta, ha una struttura simile al territorio, che spiega la sua utilità.
Le mappe sono utili perché sono astrazioni di un oggetto reale a una scala più gestibile, ma escluderanno sempre un certo livello di dettaglio. A seconda di quanta area include una mappa, potrebbe esserci anche qualche distorsione dovuta alla proiezione della mappa (causata dal complicato processo di conversione di un globo sferico in una rappresentazione piatta).
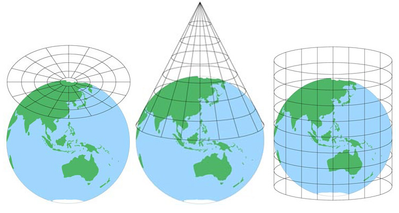
(Fonte immagine.)
L’unica mappa veramente accurata sarebbe una replica 1:1 del territorio che rappresenta. Tuttavia, una mappa del genere non sarebbe più utile che navigare nel territorio stesso.
Considera la citazione del poeta Paul Valery:
Tutto semplice è falso. Tutto ciò che è complesso è inutilizzabile.
Prende il nome da un professore di economia di Stanford, il Paradosso di Bonini descrive la sfida di creare modelli utili e completi o simulazioni di sistemi complessi. C’è spesso un atto di bilanciamento tra complessità e precisione nello sviluppo del modello. Se l’obiettivo di un modello è quello di rendere più chiara una relazione o un sistema, la complessità aggiunta sconfigge tale scopo (anche se potrebbe rendere il modello più accurato).
Ad alto livello, la relazione mappa-territorio descrive anche la relazione tra un oggetto e una rappresentazione dell’oggetto.
Se hai mai frequentato un corso di filosofia, potresti aver incontrato l’opera The Treachery of Images dell’artista surrealista Rene Magritte.

Il testo si traduce in ” Questa non è una pipa.”E non lo è. Non possiamo riempire questa immagine (digitale) con tabacco e fumarla in quanto è solo una rappresentazione di un oggetto reale.
I modelli sono astrazioni. Come le mappe, o i modelli architettonici in miniatura, o gli schemi, non possono catturare ogni dettaglio dell’oggetto o del sistema su cui sono basati, se non altro perché non esistono nel mondo reale e non funzionano allo stesso modo.

Se tutti i modelli sono sbagliati, perché preoccuparsi?
L’aforisma di George Box non è privo di critiche.
Il problema che molti statistici hanno con questa citazione sembra ampiamente rientrare in due categorie:
- I modelli sbagliati sono un’affermazione ovvia. Naturalmente tutti i modelli sono sbagliati, sono modelli.
- Questa citazione è usata come scusa per i cattivi modelli.
Lo statistico J. Michael Steele ha criticato l’adagio (vedi questo saggio personale). L’argomento principale di Steele è che “sbagliato” entra in gioco solo se il modello non risponde correttamente alla domanda a cui afferma di rispondere (ad esempio, che un edificio su una mappa è etichettato male, non che l’edificio sia rappresentato da un quadratino). Steele continua a dichiarare:
La maggior parte dei metodi statistici pubblicati ha fame di un esempio onesto.
Steele sostiene che i modelli statistici spesso non sono all’altezza di una misura di idoneità adeguata e molti modelli sviluppati dagli statistici non sono sufficienti per i loro casi d’uso previsti.
Nell’articolo La statistica come scienza, non come arte: The Way to Survive in Data Science, Mark van der Laan (Statistics at UC Berkeley) attribuisce la citazione della scatola come una causa che contribuisce a cattivi modelli statistici e la respinge come “completa assurdità.”Continua a scrivere:
La base delle statistiche ( … ) non avrebbe potuto essere quella di selezionare arbitrariamente un modello statistico “conveniente”. Tuttavia, questo è esattamente ciò che la maggior parte degli statistici fa allegramente, riferendosi con orgoglio alla citazione, ” Tutti i modelli sono sbagliati, ma alcuni sono utili.”A causa di ciò, i modelli che sono così irrealistici da essere indicizzati da un parametro dimensionale finito sono ancora lo status quo, anche se tutti sono d’accordo che sono noti per essere falsi.
Come soluzione, Van der Laan chiama gli statistici a smettere di usare la citazione di Box e si impegnano a prendere sul serio i dati, le statistiche e il metodo scientifico. Invita gli statistici a dedicare del tempo a imparare come sono stati generati i dati in un dato set di dati e si impegna a sviluppare modelli statistici realistici utilizzando tecniche di apprendimento automatico e di stima adattiva ai dati rispetto a modelli parametrici più tradizionali.
Questo articolo contiene le risposte degli statistici Michael Lavine e Christopher Tong, nonché una risposta alle risposte dell’autore originale. I due statistici che confutano indicano esempi in cui i modelli sono noti per essere sbagliati, ma sono spesso impiegati perché sono utili e adatti a un dato problema. I loro esempi includono i tre diversi modelli di luce trovati nel campo dell’ottica (ottica geometrica, ottica fisica e ottica quantistica; tutti e tre i modelli rappresentano la luce in modo diverso, sono “sbagliati” in un certo senso e sono ancora impiegati oggi) e la relazione (quasi) lineare tra il log del flusso di carbonio e la temperatura del suolo trovata nei dati raccolti
A sua volta, Van der Laan risponde a questi esempi e ad altre critiche del suo articolo, in particolare al suo concetto di trovare un modello “vero”. Le lettere di risposta sono sicuramente la pena di leggere se siete interessati. Si tratta di un’area di dibattito attiva nel campo della statistica e della scienza dei dati.
Ma alcuni modelli sono utili
Nonostante le limitazioni dei modelli, molti modelli possono essere molto utili. Poiché sono semplificati, i modelli sono spesso utili per comprendere un determinato componente o aspetto di un sistema.
Nel contesto della scienza dei dati, l’apprendimento automatico e i modelli statistici possono essere utili per stimare (prevedere) valori sconosciuti. In molti contesti, se le ipotesi del modello reggono, una stima incerta fornita da un forte modello statistico può ancora essere molto utile per prendere decisioni.
La seconda, meno citata metà della saggezza di George Box è questa:
“La domanda pratica è quanto devono essere sbagliati (i modelli) per non essere utili.”- George Box
Diamo un’altra occhiata al nostro esempio di regressione lineare:
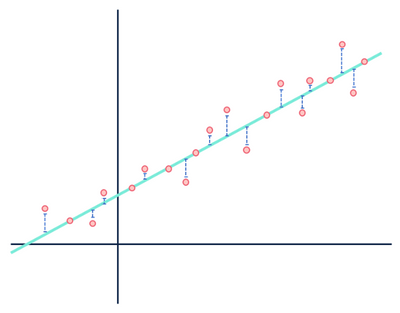
Per lo più ho passato troppo tempo su questa immagine per usarla solo una volta.
Ora, diamo un’occhiata a un altro modello di regressione lineare teorico adatto a un set di dati diverso.
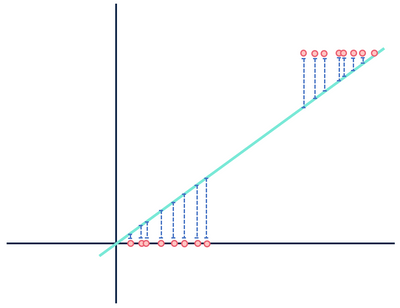
Non badare alle distanze wait aspetta questo non può essere giusto.
Entrambe le figure mostrano errori, ma un set di dati dimostra una relazione chiaramente lineare mentre l’altro è logistico. Entrambi i modelli sono “sbagliati”, ma uno cattura chiaramente una relazione reale tra le variabili, mentre l’altro no, rendendone uno utile e uno inutile. Scartare le distanze in blu come rumore è ragionevole se i dati hanno una relazione lineare, ma questa ipotesi cade a pezzi quando la relazione ha una forma funzionale diversa rispetto al modello selezionato.
Fare buoni modelli
Il fatto che i modelli siano sbagliati o limitati nell’ambito di ciò che rappresentano potrebbe sembrare ovvio a molte persone che lavorano con i modelli, ma sfortunatamente, molte persone non se ne rendono conto o ci pensano molto. Ecco perché ritengo che sia importante tenere a mente le parole di George Box quando si sviluppa un modello. Non dovrebbe essere usato come scusa per costruire cattivi modelli.
Per ulteriori letture, Steele ha alcune grandi note di classe: il modello ha senso? e il modello ha senso? Parte II: Sfruttare la sufficienza. Un’altra grande risorsa è il documento ” Tutti i modelli sono sbagliati…”: un’introduzione all’incertezza del modello da un workshop di selezione del modello tenutosi nel 2011 a Groningen.
Un’altra lettura interessante è When All Models are Wrong from Issues in Science and Technology, che richiama le parole di Box come una richiesta di maggiore trasparenza nei modelli scientifici e statistici.
La cosa importante da togliere a tutto questo è assicurarsi di capire quali aspetti dei dati vengono acquisiti dal modello e quali aspetti non lo sono. È fondamentale verificare le tue ipotesi e i punti di partenza. In qualità di statistico o scienziato dei dati, è tua responsabilità produrre modelli rigorosi e conoscere i loro limiti. Segnala sempre la tua incertezza e la portata del tuo modello. Con questo in mente, si sarà in grado di fare modelli che, mentre forse sbagliato, può certamente essere utile.
Originale. Ripubblicato con il permesso.
Bio: Un geografo di formazione e un geek di dati a cuore, Sydney crede fermamente che i dati e la conoscenza sono più preziosi quando possono essere chiaramente comunicati e compresi. Nel suo attuale ruolo di Sr. Data Science Content Engineer, passa le sue giornate a fare ciò che ama di più; trasformare le conoscenze tecniche e la ricerca in contenuti coinvolgenti, creativi e divertenti per la comunità Alteryx.
Correlati:
- I 3 più grandi errori nell’apprendimento della scienza dei dati
- 3 grandi problemi con i Big Data e come risolverli
- Scelta tra candidati modello