あなたが知っておく必要があるトップビッグデータ技術
ビッグデータ技術、あなたが最近で多くを聞くことができるバズワード。 この記事では、ビッグデータがより高い高さに到達するためにその枝を広げた画期的な技術について説明します。
- ビッグデータ技術とは何ですか?
- ビッグデータ技術の種類
- トップビッグデータ技術
- 新興ビッグデータ技術
ビッグデータ技術とは何ですか?
ビッグデータ技術は、従来のデータ処理ソフトウェアが扱うことができなかった非常に複雑で大規模なデータセットから情報を分析、処理、抽出するように設計されたソフトウェアユーティリティとして定義することができる。

この膨大な量のリアルタイムデータを分析し、将来のリスクを軽減するための結論と予測を考え出すためには、ビッグデータ処理技術が必要です。
ここでは、ビッグデータ技術が分類されているカテゴリを見てみましょう:
ビッグデータ技術の種類:
ビッグデータ技術は、主に二つのタイプに分類されます:
- 運用ビッグデータ技術
- 分析ビッグデータ技術

まず、運用上のビッグデータは、私たちが生成する通常の日々のデータに関するものです。 これは、オンライン取引、ソーシャルメディア、または特定の組織などからのデータである可能性があります。 あなたも、これは分析ビッグデータ技術を供給するために使用される生データの一種であると考えることができます。
運用ビッグデータ技術のいくつかの例は次のとおりです:
- あなたの鉄道のチケット、航空券、映画のチケットなどを含むオンラインチケット予約、
- あなたのアマゾン、フリップカート、ウォルマート、スナップディールと、より多くのオンラインショッピング。
- FacebookやInstagram、what’s appなどのソーシャルメディアサイトからのデータ。
- 多国籍企業の従業員の詳細。
だから、これで私たちは分析ビッグデータ技術に移動してみましょう。
分析ビッグデータは、ビッグデータ技術の高度なバージョンのようなものです。 これは、運用ビッグデータよりも少し複雑です。 要するに、分析的ビッグデータは、実際のパフォーマンスの部分が画像に入ってくる場所であり、重要なリアルタイムのビジネス上の意思決定は、運用ビッ
分析ビッグデータ技術のいくつかの例は次のとおりです:

- 株式マーケティング
- 情報のすべての単一のビットが重要である宇宙ミッションを実行します。
- 天気予報情報。
- 特定の患者の健康状態を監視できる医療分野。
IT業界で使用されているトップのビッグデータ技術を見てみましょう。
トップビッグデータテクノロジー
トップビッグデータテクノロジーは、以下の4つの分野に分類されています:
- データストレージ
- データマイニング
- データ分析
- データビジュアライゼーション
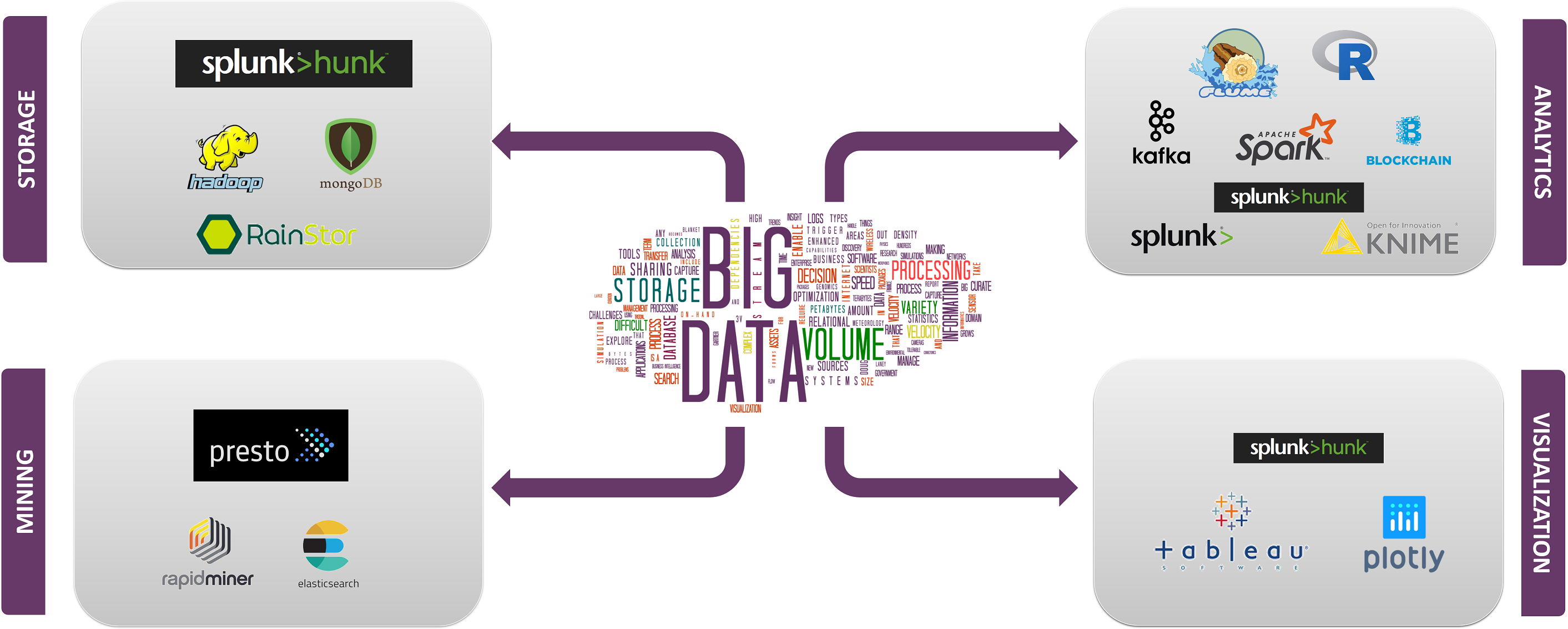
今、私たちはそれらを使用している企業と一緒に、その事実と能力を持つこれらのカテゴリのそれぞれに該当する技術に対処してみましょう。
データストレージにおけるビッグデータ技術を始めましょう。
データストレージ
Hadoop
![]()
Hadoop Frameworkは、単純なプログラミングモデルを持つコモディティハードウェアを使用して、分散データ処理環境でデータを格納し、処理するように設計されました。 それは高速および安価の異なった機械で現在のデータを貯え、分析できる。
-
-
-
-
- 2011年10月にApache Software Foundationによって開発された。
- 記述元:JAVA
- 現在の安定版:Hadoop3.11
-
-
-
Hadoopを使用している企業:
MongoDB

MongoDBのようなNoSQLドキュメントデータベースは、リレーショナルデータベースで使用されるリジッドスキーマに直接代わるものを提供します。 これにより、MongoDBは、大規模なボリュームや分散アーキテクチャ間で多種多様なデータ型を処理しながら柔軟性を提供することができます。
-
-
-
-
- 2009年11月に
- で書かれたMongoDB: C++、Go、JavaScript、Python
- 現在の安定バージョン:MongoDB4.0.10
-
-
-
MongoDBを使用している企業:

Rainstor
![]() RainStorは、大企業のビッグデータを管理および分析するために設計された同名のデータベース管理システムを開発したソフトウェア会社です。 これは、参照用に大量のデータを格納するプロセスを整理するために重複排除技術を使用しています。
RainStorは、大企業のビッグデータを管理および分析するために設計された同名のデータベース管理システムを開発したソフトウェア会社です。 これは、参照用に大量のデータを格納するプロセスを整理するために重複排除技術を使用しています。
-
-
-
-
- によって開発されました:2004年にRainStorソフトウェア会社。次のように動作します:SQL
- 現在の安定バージョン:RainStor5.5
-
-
-
RainStorを使用している企業:

ハンク

Hunkを使用すると、仮想インデックスを介してリモートHadoopクラスター内のデータにアクセスしたり、Splunk検索処理言語を使用してデータを分析したりできます。 Hunkを使用すると、HadoopおよびNoSQLデータソースから大量のレポートと視覚化を行うことができます。
-
-
-
-
- によって開発されました:2013年にSplunk INC。
- 記述元:JAVA
- 現在の安定バージョン:Splunk Hunk6.2
-
-
-
さて、データマイニングで使用されるビッグデータ技術に移りましょう。
データマイニング
さきがけ

Prestoは、ギガバイトからペタバイトまでのすべてのサイズのデータソースに対して対話型の分析クエリを実行するためのオープンソースの分散SQLクエリエン Prestoでは、Hive、Cassandra、リレーショナルデータベース、独自のデータストア内のデータを照会できます。
-
-
-
-
- によって開発されました:2013年のApache財団。Java
- 現在の安定バージョン:Presto0。22
-
-
-
さきがけを利用している企業:

ラピッドマイナー
![]()
RapidMinerは、ユーザーが予測分析を作成、配信、および維持することを可能にする非常に強力で堅牢なグラフィカルユーザーインターフェイスを備えた集中型ソリューシ これは、いくつかの言語でのサポートをスクリプト、非常に高度なワークフローを作成することができます。
-
-
-
-
- によって開発された: 2001年のRapidMiner
- 記述元:JAVA
- 現在の安定版:RapidMiner9.2
-
-
-
RapidMinerを使用している企業:

Elasticsearch
![]()
ElasticsearchはLuceneライブラリに基づく検索エンジンです。 これは、HTTP WebインターフェイスとスキーマフリーのJSONドキュメントを備えた分散型のマルチテナント対応のフルテキスト検索エンジンを提供します。
-
-
-
-
- によって開発された: 2012年のエラスティックNV。
- 記述元:JAVA
- 現在の安定バージョン:ElasticSearch7.1
-
-
-
Elasticsearchを使用している企業:

これにより、データ分析で使用されるビッグデータ技術に移行することができます。
データ分析
カフカ

Apache Kafkaは分散ストリーミングプラットフォームです。 ストリーミングプラットフォームには、次の3つの主要な機能があります。:
-
-
-
-
- パブリッシャー
- サブスクライバー
- コンシューマー
-
-
-
これは、メッセージキューやエンタープライズメッセージングシステムに似ています。
- 開発者:2011年のApache Software Foundation
- 執筆者:Scala、JAVA
- 現在の安定版:Apache Kafka2.2.0
カフカを利用している企業:

Splunk
 Splunkは、グラフ、レポート、アラート、ダッシュボード、およびデータの視覚化を生成することができる検索可能なリポジトリ内のリアルタイムデータをキャプ また、アプリケーション管理、セキュリティ、コンプライアンス、ビジネス分析、Web分析にも使用されます。
Splunkは、グラフ、レポート、アラート、ダッシュボード、およびデータの視覚化を生成することができる検索可能なリポジトリ内のリアルタイムデータをキャプ また、アプリケーション管理、セキュリティ、コンプライアンス、ビジネス分析、Web分析にも使用されます。
-
-
-
-
- 開発者:Splunk INC in the year2014 6th May
- 執筆者:AJAX,C++,Python,XML
- 現在の安定版:Splunk7.3
-
-
-
Splunkを使用している企業:

KNIME
 KNIMEを使用すると、データフローを視覚的に作成し、一部またはすべての分析ステップを選択的に実行し、結果、モデル、および対話型ビューを検査できます。 KNIMEはJavaで書かれており、Eclipseに基づいており、追加の機能を提供するプラグインを追加するために、その拡張メカニズムを利用しています。
KNIMEを使用すると、データフローを視覚的に作成し、一部またはすべての分析ステップを選択的に実行し、結果、モデル、および対話型ビューを検査できます。 KNIMEはJavaで書かれており、Eclipseに基づいており、追加の機能を提供するプラグインを追加するために、その拡張メカニズムを利用しています。
-
-
-
-
- 2008年のKNIME
- で書かれた: JAVA
- 現在の安定バージョン:KNIME3.7.2
-
-
-
KNIMEを使用している企業:
 スパーク
スパーク

Sparkは、スピードを提供するインメモリコンピューティング機能、さまざまなアプリケーションをサポートするための一般化された実行モデル、および開発を容易にするためのJava、Scala、およびPython Apiを提供します。
-
-
-
-
- 開発者:Apache Software Foundation
- 執筆者:Java、Scala、Python、R
- 現在の安定バージョン:Apache Spark2.4。3
-
-
-
Sparkを利用している企業:

R-Language

Rは、統計計算とグラフィックスのためのプログラミング言語とフリーソフトウェア環境です。 R言語は、統計ソフトウェアを開発するために統計学者やデータマイナーの間で広く使用されており、主にデータ分析に使用されています。
-
-
-
-
- 開発者:R-Foundation in the year2000 29th Feb
- 記述元:Fortran
- 現在の安定版:R-3.6.0
-
-
-
R言語を使用している企業:

Blockchain
![]() BlockChainは、支払い、エスクロー、タイトルなどの不可欠な機能で使用され、詐欺を減らし、金融プライバシーを高め、取引をスピードアップし、市場を国際化することができます。
BlockChainは、支払い、エスクロー、タイトルなどの不可欠な機能で使用され、詐欺を減らし、金融プライバシーを高め、取引をスピードアップし、市場を国際化することができます。
ブロックチェーンは、ビジネスネットワーク環境で以下を達成するために使用することができます:
-
-
-
-
- 共有元帳: ここでは、ビジネスネットワークを介してレコードの分散システムを追加することができます。
- スマートコントラクト:取引データベースにビジネス用語が埋め込まれ、取引で実行されます。
- プライバシー:適切な可視性を確保し、取引は安全で、認証され、検証可能です
- コンセンサス:ビジネスネットワーク内のすべての当事者は、ネットワーク検証
-
-
-
- 開発者:Bitcoin
- 記述元:JavaScript、C++、Python
- 現在の安定版:Blockchain4。0
ブロックチェーンを利用している企業:

これにより、データの可視化に移行しますビッグデータ技術
データの可視化
Tableau

Tableauは、ビジネスインテリジェンス業界で使用される強力で最も急速に成長しているデータ可視化ツールです。 Tableauではデータ分析が非常に高速で、作成されたビジュアライゼーションはダッシュボードやワークシートの形で行われます。
-
-
-
-
- 開発者:TableAU2013May17th
- Written in: JAVA、C++、Python、C
- 現在の安定バージョン:TableAU8.2
-
-
-
Tableauを使用している企業:

Plotly
![]()
主にグラフをより速く、より効率的に作成するために使用されます。 Python、R、MATLAB、Node用のAPIライブラリ。js、Julia、ArduinoとREST API。 Plotlyは、Jupyter notebookで対話型グラフをスタイルするためにも使用できます。
-
-
-
-
- によって開発された: 2012年のPlotly
- 記述元:JavaScript
- 現在の安定版:Plotly1.47.4
-
-
-
Plotlyを使用している企業:
 今、私たちは新興ビッグデータ技術を議論してみましょう
今、私たちは新興ビッグデータ技術を議論してみましょう
新興ビッグデータ技術
TensorFlow

TensorFlowには、ツール、ライブラリ、コミュニティリソースの包括的で柔軟なエコシステムがあり、研究者は最先端の機械学習を推進し、開発者は機械学習を搭載したアプリケーションを簡単に構築して展開できます。
-
-
-
-
- 開発者:2019年のGoogle Brainチーム
- で書かれました: Python、C++、CUDA
- 現在の安定バージョン:TensorFlow2.0beta
-
-
-
TensorFlowを使用している企業:

ビーム
![]()
Apache Beamは、多様な実行エンジンやランナ全体で実行できる高度な並列データ処理パイプラインを構築するための移植可能なAPIレイヤーを提供します。
-
-
-
-
- によって開発された: Apache Software Foundation in the year2016June15th
- で書かれたもの:JAVA、Python
- 現在の安定版:Apache Beam0.1.0incubating。
-
-
-
Beamを利用している企業:
 ドッカー
ドッカー

Dockerは、コンテナを使用してアプリケーションの作成、デプロイ、および実行を容易にするために設計されたツールです。 コンテナを使用すると、開発者はライブラリやその他の依存関係など、必要なすべての部分でアプリケーションをパッケージ化し、すべてを1つのパッケー
-
-
-
-
- 2003年1月3日にドッカー社によって開発されました。
- 執筆者:Go
- 現在の安定バージョン:Docker18.09
-
-
-
Dockerを使用している企業:

Airflow
![]() Apache Airflowは、データパイプラインの作成と管理に使用できるワークフローの自動化とスケジューリングシステムです。 Airflowでは、タスクの有向非循環グラフ(Dag)で構成されたワークフローを使用します。 コードでワークフローを定義することで、保守、テスト、バージョニングが容易になります。
Apache Airflowは、データパイプラインの作成と管理に使用できるワークフローの自動化とスケジューリングシステムです。 Airflowでは、タスクの有向非循環グラフ(Dag)で構成されたワークフローを使用します。 コードでワークフローを定義することで、保守、テスト、バージョニングが容易になります。
-
-
-
-
- 開発者:Apache Software Foundation on May15th2019
- 執筆者:Python
- 現在の安定バージョン:Apache AirFlow1.10.3
-
-
-
エアフローを使用している企業:

Kubernetes
 Kubernetesはベンダーに依存しないクラスターとコンテナ管理ツールで、2014年にGoogleによってオープンソース化されました。 これは、ホストのクラスター間でアプリケーションコンテナの自動化、デプロイ、スケーリング、および操作のためのプラットフォームを提供します。
Kubernetesはベンダーに依存しないクラスターとコンテナ管理ツールで、2014年にGoogleによってオープンソース化されました。 これは、ホストのクラスター間でアプリケーションコンテナの自動化、デプロイ、スケーリング、および操作のためのプラットフォームを提供します。
-
-
-
-
- 開発者:Cloud Native Computing Foundation in the year2015 21st of July
- 執筆者:Go
- 現在の安定版:Kubernetes1.14
-
-
-
Kubernetesを使用している企業:

これで、私たちはこの記事の終わりに来ます。 私はビッグデータとその技術に関するあなたの知識にいくつかの光を投げている願っています。
ビッグデータとその技術を理解したので、世界中に250,000人以上の満足した学習者のネットワークを持つ信頼できるオンライン学習会社EdurekaによるHadoopトレーニン EdurekaビッグデータHadoop認定トレーニングコースは、小売、ソーシャルメディア、航空、観光、金融ドメインのリアルタイムユースケースを使用して、HDFS、Yarn、MapReduce、Pig、Hive、Hbase、Oozie、Flume、Sqoopの専門家にな