Aggregate()関数を作成しました
RのAggregate()関数は、データをサブセットに分割し、各サブセットの要約統計を計算し、結果をgroup by形式で返します。 Rの集計関数は、SQLのgroup byに似ています。 Aggregate()関数は、sum、count、mean、minimum、Maximumなどのすべての集計操作を実行するのに便利です。
次の例を見てみましょう
- Aggregate()グループ合計を計算します
- aggregate()関数を使用してグループの最大値と最小値を計算します
- Aggregate()関数を使用してグループの平均を計算します
- aggregate()関数を使用してグループカウントを取得します
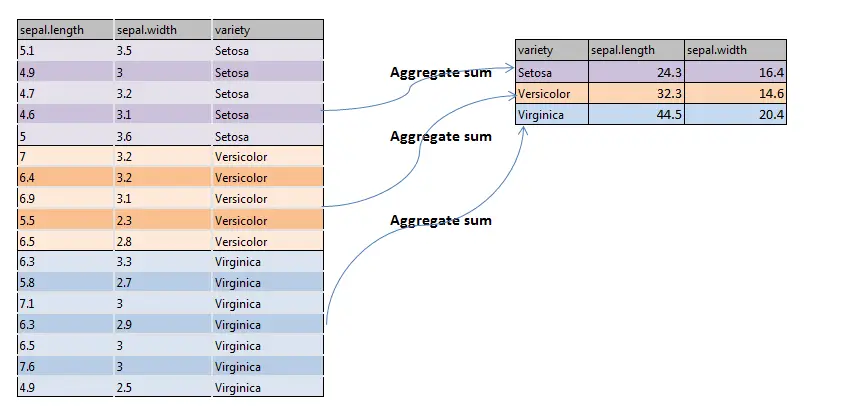
A aggregate()関数の絵文字表現、すなわち集計合計は、rの
RのAggregate()関数の構文:
| X | Rオブジェクト、主にdataframe |
| によってサブセットがグループ化されるグループ化要素のリスト | |
| FUN | 要約統計量を計算する関数 |
| simplify | 可能であれば、結果をベクトルまたは行列に単純化する必要があるかどうかを示す論理 |
| drop | グループ化値の未使用の組み合わせを削除するかどうかを示す論理値。 |
RでのAggregate()関数の例:
rでのaggregate関数の簡単な例を示すためにirisデータセットを使用しましょう。 すべてのメトリックの平均を求めたいとします(Sepal。長さのがく片。幅の花弁。長さの花弁。異なる種の場合、集計関数
# Aggregate function in R with mean summary statisticsagg_mean = aggregate(iris,by=list(iris$Species),FUN=mean, na.rm=TRUE)agg_mean
上記のコードは、各グループの平均を計算することにより、アイリスデータセットの最初の4列を取り、「種」でグループ化するた1
メモ: Aggregate()関数を使用する場合、by変数はリストに含まれている必要があります。
sumを使用したrのaggregate()関数の例:
rのaggregate()関数を使用して、種間のすべてのメトリックの合計を作成し、種ごとにグループ化しましょう。上記のコードを実行すると、出力はRの

countを使用したRのaggregate()関数の例:
aggregate()関数を使用して、種と種ごとにグループ化されたすべてのメトリックのカウントを作成しましょう。上記のコードは、虹彩データセットの最初の4列を取り、各グループのカウントを計算して「種」でグループ化するため、出力はRの
最大値を持つRのaggregate()関数の例:
aggregate()関数を使用して、種と種ごとのグループ全体のすべてのメトリックの最大値を作成しましょう。上記のコードは、虹彩データセットの最初の4列を取り、各グループの最大値を計算して「種」でグループ化するため、出力はRの

最小値を持つRのaggregate()関数の例:
aggregate()関数を使用して、種と種ごとのグループ全体のすべてのメトリックの最小値を作成しましょう。上記のコードは、アイリスデータセットの最初の4列を取り、各グループの最小値を計算して「種」でグループ化するため、出力はR5の
