KDnuggets
シドニー Firmin、Alteryxによって。
“基本的に、すべてのモデルは間違っていますが、一部のモデルは便利です。”-ジョージボックス
この有名なジョージボックスの引用は、1976年にアメリカ統計協会のジャーナルに掲載された論文”科学と統計”に最初に記録されました。 これは、統計と分析モデルの分野への重要な引用であり、二つの部分に展開することができます。
すべてのモデルが間違っている
このステートメントを掘り下げるには、モデルが何であるかを定義して調べる必要があります。
この記事の文脈では、モデルはシステムまたはオブジェクトの単純化された表現と考えることができます。 統計モデルは、データとそれが収集され、適用された環境についての仮定を行うことによって、データセット内のパターンを近似します。
統計モデルによって行われる仮定の三つの広範なカテゴリは、分布仮定(変数内の値の分布または観測誤差の分布に関する仮定)、構造的仮定(変数間の関
たとえば、線形回帰モデルは、データセット内の変数間の関係が線形(線形のみ)であることを前提としています。 線形モデルの目では、データセットを構成する観測値とモデル化された線との間の距離は単なるノイズ(つまり、データのランダムまたは原因不明のゆらぎ)であり、最終的には無視することができます。
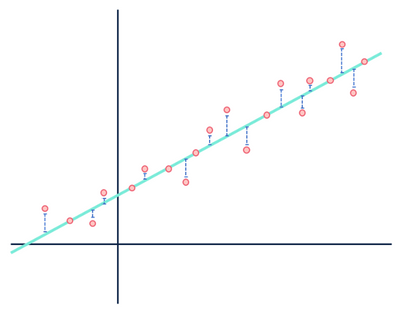
青の距離に心を払わないでください。
George Boxは、すべてのモデルは統計モデルの文脈において特に間違っていると述べた。 モデルの本質は何かの単純化された理想化された表現であるため、すべてのモデルはある意味で間違っています。 真実が現実を完全に代表することを意味するならば、モデルは決して”真実”ではありません。 モデルは仮定が保持されているときにのみ本当に役立つので、モデルを生成する際に行われた仮定を考慮することは非常に重要です。
マップとミニチュア
ボックスの”すべてのモデルが間違っている”と同様の観測は、多くの異なる分野に存在しています。
Alfred Korzybskiに起因する地図-領土関係を参照する格言があります:
地図はそれが表す領土ではありませんが、正しい場合、地図はその有用性を説明する領土と同様の構造を持っています。
マップは、より管理しやすいスケールで実際のオブジェクトの抽象化であるため便利ですが、常にある程度の詳細レベルを除外します。 マップに含まれる領域の量によっては、マップの投影に起因する歪みが発生することもあります(球面を平らな表現に変換するトリッキーなプロセスに
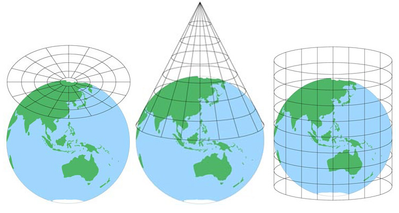
(イメージソース。)
真に正確な地図は、それが表す領土の1:1複製であるだけです。 しかし、そのような地図は、領土自体をナビゲートするよりも有用ではありません。
詩人ポール-ヴァレリーからの引用を考えてみましょう:
単純なものはすべて偽です。 複雑なものはすべて使用できません。
スタンフォード大学の教授にちなんで命名されたボニーニのパラドックスは、複雑なシステムの有用で完全なモデルやシミュレーションを作成する モデル開発の複雑さと正確さの間には、しばしばバランスの取れた行為があります。 モデルの目標が関係やシステムをより明確にすることである場合、複雑さが増すとその目的が損なわれます(モデルがより正確になる可能性があ
高レベルでは、map-territoryリレーションシップは、オブジェクトとオブジェクトの表現との関係も記述します。
哲学の授業を受けたことがあれば、シュルレアリスムの芸術家ルネ-マグリットの作品”イメージの裏切り”に遭遇したかもしれません。

テキストは”これはパイプではありません。”そして、それはありません。 この(デジタル)画像にタバコを詰め込んで喫煙することはできません。
モデルは抽象化されています。 地図、ミニチュア建築モデル、回路図のように、現実世界に存在せず、同じように機能しないという理由だけで、基づいているオブジェクトやシステムの

すべてのモデルが間違っている場合は、なぜ気に?
ジョージ-ボックスの格言は、その批評家がいないわけではありません。
多くの統計学者がこの引用で持っている問題は、広く二つのカテゴリに分類されるようです:
- モデルが間違っていることは明らかな声明です。 もちろん、すべてのモデルは間違っている、彼らはモデルです。
- この引用は悪いモデルの言い訳として使われています。
統計学者J.Michael Steeleはこの格言に批判的である(この個人的なエッセイを参照)。 Steeleの主な議論は、モデルが答えると主張する質問に正しく答えない場合にのみ、「間違った」ことが起こるということです(例:、地図上の建物が誤ってラベル付けされていること、建物が小さな正方形で表されていることではありません)。 スティールは、状態に続きます:
公開されている統計的手法の大部分は、正直な例のために飢えています。
Steeleは、統計モデルはしばしば適切な適合度尺度に達しておらず、統計学者によって開発された多くのモデルは意図されたユースケースには十分ではないと主張している。
の記事では、科学としての統計ではなく、芸術ではありません: データサイエンスで生き残るための方法、Mark van der Laan(UC Berkeleyの統計学)は、ボックスの引用を悪い統計モデルの貢献の原因とみなし、それを「完全なナンセンス。”彼は書くことになります:
統計(…)の基礎は、「便利な」統計モデルを任意に選択することではありませんでした。 しかし、それは正確にほとんどの統計学者が軽率に行うことであり、誇らしげに引用を参照して、”すべてのモデルは間違っていますが、いくつかは有用で”このため、有限次元パラメータで索引付けされるほど非現実的なモデルは、誰もが偽であることが知られているにもかかわらず、現状のままです。
解決策として、Van der Laanは統計学者にBoxの引用の使用をやめ、データ、統計、科学的方法を真剣に取ることを約束するよう呼びかけています。 彼は、統計学者に、与えられたデータセット内のデータがどのように生成されたかを学ぶ時間を費やし、より伝統的なパラメトリックモデルよりも機械学習とデータ適応推定技術を使用して現実的な統計モデルを開発することにコミットするよう呼びかけています。
この記事には、統計学者のMichael LavineとChristopher Tongからの回答と、元の著者からの回答に対する回答があります。 二人の反論統計学者は、モデルが間違っていることが知られているが、有用であり、与えられた問題に適合するためにしばしば採用される例を指摘する。 それらの例には、光学の分野で見つかった三つの異なる光のモデル(幾何学的光学、物理光学、量子光学、三つのモデルはすべて光を異なって表し、ある意味では”間違っている”、そして今日でも採用されている)、ハーバードの森で収集されたデータに見られる炭素フラックスの対数と土壌温度の間の(ほぼ)線形関係が含まれる。
順番に、ファン*デル*ラーンは、これらの例や彼の記事の他の批判、具体的には”真の”モデルを見つけるという彼の概念に応答します。 あなたが興味を持っている場合は、応答の手紙は間違いなく読む価値があります. これは、統計とデータ科学の分野で活発な議論の分野を表しています。
しかし、いくつかのモデルは便利です
モデルの制限にもかかわらず、多くのモデルは非常に便利です。 これらは単純化されているため、モデルはシステムの特定のコンポーネントまたはファセットを理解するのに役立ちます。
データサイエンスの文脈では、機械学習と統計モデルは未知の値を推定(予測)するのに役立ちます。 多くの状況では、モデルの仮定が保持されている場合、強力な統計モデルによって提供される不確実な推定値は、意思決定に非常に役立ちます。
ジョージ-ボックスの知恵の第二、あまり引用されていない半分はこれです:
“実用的な問題は、do(モデル)が役に立たないようにする必要があるかどうかです。”-George Box
線形回帰の例をもう一度見てみましょう:
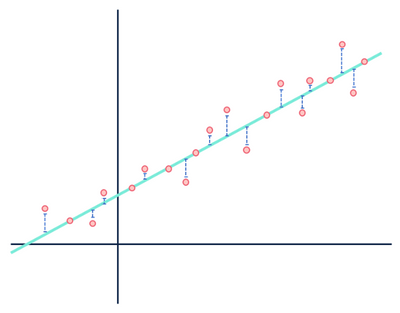
主に私は一度だけそれを使用するには、この画像にあまりにも多くの時間を費やしました。
さて、別のデータセットに適合する別の理論的線形回帰モデルを見てみましょう。
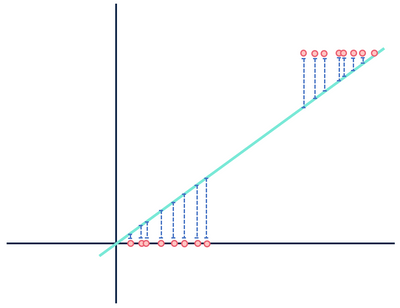
距離に気を払わない…これは正しいことはできません待ってください。
両方の図はエラーを示していますが、一方のデータセットは明確に線形の関係を示し、他方はロジスティックです。 両方のモデルは”間違っている”が、一方は変数間の実際の関係を明確に捉え、他方はそうではなく、一方は有用であり、他方は役に立たない。 データに線形関係がある場合、ノイズとして青の距離を破棄することは妥当ですが、関係が選択したモデルとは異なる機能形状を持つ場合、この仮定は
良いモデルを作る
モデルが間違っているか、表現の範囲が限られているという事実は、モデルを扱う多くの人にとって明らかに見えるかもしれ だからこそ、モデルを開発する際には、George Boxの言葉を念頭に置いておくことが重要だと感じています。 それは悪いモデルを構築するための言い訳として使用すべきではありません。
さらに読むために、Steeleはいくつかの素晴らしいクラスノートを持っています:モデルは理にかなっていますか? そして、モデルは意味をなさないのですか? 第二部:充足を利用する。 もう一つの大きなリソースは、フローニンゲンで2011年に開催されたモデル選択ワークショップからの”すべてのモデルは間違っている…”という論文です。
もう一つの興味深い読みは、すべてのモデルが科学技術の問題から間違っているときであり、科学的および統計的モデルのより厳格な透明性のための呼び出しとしてボックスの言葉を呼び出しています。
このすべてから取り除く重要なことは、データのどの側面がモデルによってキャプチャされ、どの側面がキャプチャされないかを理解することです。 あなたの仮定と出発点を確認することが重要です。 統計学者またはデータサイエンティストとして、厳密なモデルを作成し、その限界を知ることはあなたの責任です。 不確実性とモデルの範囲を常に報告してください。 それを念頭に置いて、おそらく間違っているかもしれませんが、確かに有用なモデルを作ることができます。
許可を得て再投稿。
: トレーニングと中心にデータオタクによる地理学者、シドニーは強く、彼らが明確に伝達され、理解することができるときにデータと知識が最も価値がある Sr.Data Scienceコンテンツエンジニアとしての彼女の現在の役割では、彼女は彼女が一番好きなことをやって彼女の日を過ごすことになります。
関連:
- 学習データサイエンスにおける3つの最大の間違い
- ビッグデータの3つの大きな問題とその解決方法
- モデル候補の選択