KDnuggets
Af Sydney Firmin, Altery.
“i det væsentlige er alle modeller forkerte, men nogle modeller er nyttige.”- George boks
dette berømte George boks citat blev først optaget i 1976 i papiret “videnskab og statistik”, der blev offentliggjort i Journal of the American Statistical Association. Det er et vigtigt citat på området statistik og analytiske modeller og kan pakkes ud i to dele.
Alle modeller er forkerte
for at grave i denne erklæring skal vi definere og undersøge, hvad en model er.
i forbindelse med denne artikel kan en model betragtes som en forenklet repræsentation af et system eller objekt. Statistiske modeller tilnærmer mønstre i et datasæt ved at tage antagelser om dataene såvel som det miljø, det blev samlet i og anvendt på.
de tre brede kategorier af antagelser foretaget af statistiske modeller er fordelingsantagelser (antagelser om fordelingen af værdier i en variabel eller fordelingen af observationsfejl), strukturelle antagelser (antagelser om det funktionelle forhold mellem variabler) og krydsvariationsantagelser (fælles sandsynlighedsfordeling).
for eksempel antager en lineær regressionsmodel, at forholdet mellem variabler i et datasæt er lineært (og kun lineært). I øjnene af en lineær model er enhver afstand mellem observationerne, der udgør datasættet og den modellerede linje, bare støj (dvs.tilfældige eller uforklarlige udsving i dataene) og kan i sidste ende ignoreres.
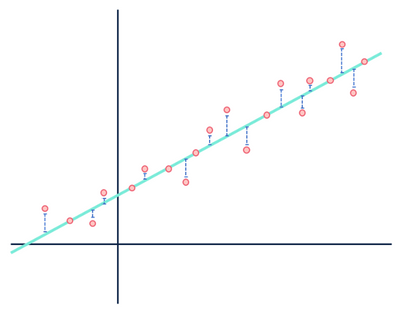
vær ikke opmærksom på afstandene i blåt.
George boks erklærede, at alle modeller er forkerte specifikt i forbindelse med statistiske modeller. Fordi selve karakteren af en model er en forenklet og idealiseret repræsentation af noget, vil alle modeller være forkerte på en eller anden måde. Modeller vil aldrig være “sandheden”, hvis sandheden betyder helt repræsentativ for virkeligheden. Det er meget vigtigt at overveje antagelserne om at generere en model, fordi modeller kun er virkelig nyttige, når antagelserne holdes op.
kort og miniaturer
lignende observationer til boksens “alle modeller er forkerte” findes i mange forskellige felter.
der er en aforisme, der refererer til kort-territorium-forholdet, tilskrevet Alfred Korsybski:
et kort er ikke det område, det repræsenterer, men hvis det er korrekt, har det en lignende struktur som territoriet, der tegner sig for dets anvendelighed.
kort er nyttige, fordi de er abstraktioner af et rigtigt objekt i en mere håndterbar skala, men de vil altid udelukke noget detaljeringsniveau. Afhængigt af hvor meget område et kort inkluderer, kan der også være en vis forvrængning på grund af projektionen af kortet (forårsaget af den vanskelige proces med at konvertere en sfærisk klode til en flad repræsentation).
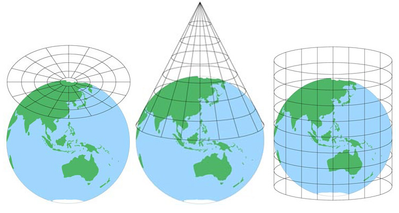
(billede kilde.)
det eneste virkelig nøjagtige kort ville være en 1:1-replikation af det område, det repræsenterer. Et sådant kort ville dog ikke være mere nyttigt end at navigere i selve territoriet.
overvej citatet fra digteren Paul Valery:
alt simpelt er falsk. Alt, hvad der er komplekst, er ubrugeligt.
opkaldt efter en Stanford-erhvervsprofessor beskriver Boninis paradoks udfordringen med at skabe nyttige, komplette modeller eller simuleringer af komplekse systemer. Der er ofte en balancegang mellem kompleksitet og nøjagtighed i modeludvikling. Hvis målet med en model er at gøre et forhold eller et system klarere, besejrer tilføjet kompleksitet dette formål (selvom det muligvis gør modellen mere nøjagtig).
på et højt niveau beskriver kort-territorium-forholdet også forholdet mellem et objekt og en repræsentation af objektet.
hvis du nogensinde har taget en filosofiklasse, er du måske stødt på værket forræderiet med billeder af den surrealistiske kunstner Rene Magritte.

teksten oversættes til ” dette er ikke et rør.”Og det er det ikke. Vi kan ikke fylde dette (digitale) billede med tobak og ryge det, da det kun er en repræsentation af et rigtigt objekt.
modeller er abstraktioner. Ligesom kort eller miniature arkitektoniske modeller eller skemaer kan de ikke fange alle detaljer i det objekt eller system, de er baseret på, hvis kun fordi de ikke findes i den virkelige verden og ikke fungerer på samme måde.

Hvis Alle Modeller Er Forkerte, Hvorfor Gider?
George boksens aforisme er ikke uden sine kritikere.
det problem, mange statistikere har med dette citat, synes stort set at falde i to kategorier:
- modeller, der tager fejl, er en åbenbar erklæring. Selvfølgelig er alle modeller Forkerte, de er modeller.
- dette citat bruges som en undskyldning for dårlige modeller.
statistiker J. Michael Steele har været kritisk over for ordsproget (se dette personlige essay). Steeles primære argument er ,at” forkert ” kun kommer i spil, hvis modellen ikke svarer korrekt på det spørgsmål, som den hævder at besvare (f. eks., at en bygning på et kort er forkert mærket, ikke at bygningen er repræsenteret af en lille firkant). Steele fortsætter med at oplyse:
de fleste offentliggjorte statistiske metoder hungrer efter et ærligt eksempel.
Steele hævder, at statistiske modeller ofte ikke er op til en passende fitnessforanstaltning, og mange modeller udviklet af statistikere er ikke tilstrækkelige til deres tilsigtede brugssager.
i artiklen statistik som en videnskab, ikke en kunst: Vejen til at overleve inden for Datalogi, Mark van der Laan (statistik ved UC Berkeley) tilskriver boksens citat som en medvirkende årsag til dårlige statistiske modeller og afviser det som “komplet vrøvl.”Han fortsætter med at skrive:
grundlaget for statistik (…) kunne ikke have været vilkårligt at vælge en “praktisk” statistisk model. Imidlertid, det er netop, hvad de fleste statistikere blithely gør, stolt med henvisning til citatet, “Alle modeller er forkerte, men nogle er nyttige.”På grund af dette er modeller, der er så urealistiske, at de er indekseret af en endelig dimensionel parameter, stadig status, selvom alle er enige om, at de vides at være falske.
som en løsning opfordrer Van der Laan statistikere til at stoppe med at bruge boksens citat og forpligte sig til at tage data, statistik og den videnskabelige metode alvorligt. Han opfordrer statistikere til at bruge tid på at lære, hvordan data i et givet datasæt blev genereret og forpligte sig til at udvikle realistiske statistiske modeller ved hjælp af maskinindlæring og dataadaptive estimeringsteknikker frem for mere traditionelle parametriske modeller.
denne artikel har svar fra statistikere Michael Lavine og Christopher Tong samt et svar på svarene fra den oprindelige forfatter. De to tilbagevirkende statistikere peger på eksempler, hvor modeller vides at være forkerte, men ofte anvendes, fordi de er nyttige og egnede til et givet problem. Deres eksempler inkluderer de tre forskellige lysmodeller, der findes inden for optik (geometrisk optik, fysisk optik og kvanteoptik; alle tre modeller repræsenterer lys forskelligt, er “forkerte” på en eller anden måde og anvendes stadig i dag) og det (næsten) lineære forhold mellem loggen over kulstofflukningen og jordtemperaturen, der findes i data indsamlet i Harvard Forest.
til gengæld reagerer Van der Laan på disse eksempler og andre kritikker af sin artikel, specifikt hans koncept om at finde en “sand” model. Svarbrevene er bestemt værd at læse, hvis du er interesseret. Dette repræsenterer et aktivt debatområde inden for statistik og datalogi.
men nogle modeller er nyttige
på trods af modellernes begrænsninger kan mange modeller være meget nyttige. Fordi de er forenklede, er modeller ofte nyttige til at forstå en bestemt komponent eller facet af et system.
i forbindelse med datalogi kan maskinindlæring og statistiske modeller være nyttige til at estimere (forudsige) ukendte værdier. I mange sammenhænge, hvis modelens antagelser holder op, kan et usikkert skøn fra en stærk statistisk model stadig være meget nyttigt til at træffe beslutninger.
den anden, mindre citerede halvdel af George bokses visdom er dette:
“det praktiske spørgsmål er, hvordan forkert skal (modeller) være for ikke at være nyttigt.”- George boks
lad os tage et andet kig på vores lineære regressionseksempel:
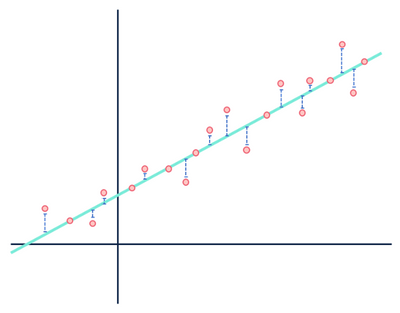
for det meste brugte jeg for meget tid på dette billede til at bruge det bare en gang.
lad os nu se på en anden teoretisk lineær regressionsmodel, der passer til et andet datasæt.
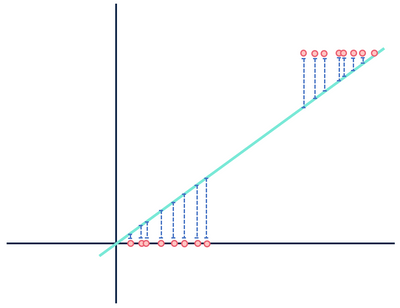
vær ikke opmærksom på afstandene … vent, det kan ikke være rigtigt.
begge tal viser fejl, men det ene datasæt viser et klart lineært forhold, mens det andet er logistisk. Begge modeller er “forkerte”, men man fanger tydeligt et reelt forhold mellem variabler, mens den anden ikke gør det, hvilket gør en nyttig og en ubrugelig. Det er rimeligt at kassere afstandene i blåt som støj, hvis dataene har et lineært forhold, men denne antagelse falder fra hinanden, når forholdet har en anden funktionel form end din valgte model.
at lave gode modeller
det faktum, at modeller er forkerte eller begrænsede i omfanget af det, de repræsenterer, kan virke indlysende for mange mennesker, der arbejder med modeller, men desværre er mange mennesker ikke klar over det eller tænker meget over det. Derfor føler jeg, at det er vigtigt at huske George-boksens ord, når man udvikler en model. Det bør ikke bruges som en undskyldning for at bygge dårlige modeller.
for yderligere læsning har Steele nogle gode klassenoter: giver modellen mening? giver modellen mening? Del II: udnyttelse af tilstrækkelighed. En anden stor ressource er papiret ‘ alle modeller er forkerte…’: En introduktion til modelusikkerhed fra et modelvalgsværksted, der blev afholdt i 2011 i Groningen.
en anden interessant læsning er, når alle modeller er forkerte Fra spørgsmål inden for videnskab og teknologi, der opfordrer til boksens ord som en opfordring til strengere gennemsigtighed i videnskabelige og statistiske modeller.
den vigtige ting at tage væk fra alt dette er at sikre, at du forstår, hvilke aspekter af dine data der er fanget af din model, og hvilke aspekter der ikke er. Det er vigtigt at kontrollere dine antagelser og udgangspunkt. Som statistiker eller dataforsker er det dit ansvar at producere strenge modeller samt kende deres begrænsninger. Rapporter altid din usikkerhed såvel som omfanget af din model. Med det i tankerne vil du være i stand til at lave modeller, der, selvom de muligvis er forkerte, helt sikkert kan være nyttige.
Original. Reposted med tilladelse.
Bio: En geograf ved træning og en datanørd i hjertet, Sydney er overbevist om, at data og viden er mest værdifulde, når de klart kan kommunikeres og forstås. I sin nuværende rolle som Sr. Data Science Content Engineer, hun får tilbringe sine dage med at gøre det, hun elsker bedst; omdanne teknisk viden og forskning til engagerende, kreativ, og sjovt indhold til Altery-samfundet.
relateret:
- de 3 største fejl ved læring af datalogi
- 3 store problemer med Big Data og hvordan man løser dem
- valg mellem Modelkandidater