Aggregate () functie in R
Aggregate() functie in R splitst de gegevens in subsets, berekent samenvattende statistieken voor elke subsets en retourneert het resultaat in een groep op vorm. Aggregate functie in R is vergelijkbaar met groep door in SQL. De functie Aggregate () is nuttig bij het uitvoeren van alle geaggregeerde bewerkingen zoals Som,aantal,gemiddelde, minimum en Maximum.
Laat een Voorbeeld zien van de volgende
- Aggregate () – die berekent groep som
- bereken de groep maximum en minimum gebruik van de functie aggregate ()
- Aggregate () – functie die berekent groep gemiddelde
- Voor groep telt met behulp van de functie aggregate ()
Een pictographical vertegenwoordiging van de aggregate() functie d.w.z. de som is hieronder weergegeven
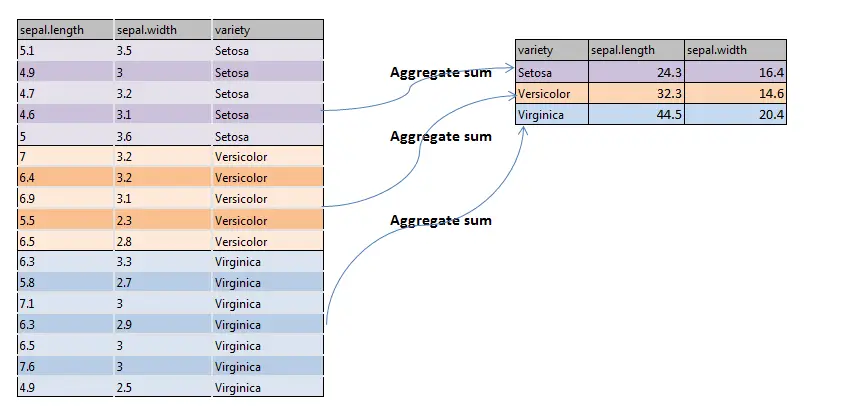
Syntaxis voor de Functie Aggregate() in R:
| X | een R-object, Meestal een dataframe |
| door | een lijst van de groepering van elementen, die door de subsets worden gegroepeerd door |
| LEUK | een functie voor het berekenen van de samenvattende statistieken |
| vereenvoudigen | een logische aangeeft of de resultaten moeten worden vereenvoudigd tot een vector of matrix als mogelijk |
| drop | een logische aangeeft of te laten vallen ongebruikte combinaties van waarden groeperen. |
voorbeeld van Aggregate () functie in R:
laten we de iris data set gebruiken om een eenvoudig voorbeeld van aggregate functie in R. We weten allemaal over iris dataset. Stel dat als willen het gemiddelde van alle metrics te vinden (Sepal.Lengte Kelkblad.Breedte Bloemblaadje.Lengte Bloemblaadje.Breedte) voor de verschillende soorten dan kunnen we gebruik maken van aggregate functie
# Aggregate function in R with mean summary statisticsagg_mean = aggregate(iris,by=list(iris$Species),FUN=mean, na.rm=TRUE)agg_mean
de bovenstaande code neemt de eerste 4 kolommen van iris data set en groepen door “species” door het berekenen van het gemiddelde voor elke groep, dus de output zal

opmerking: Bij gebruik van de functie aggregate() moeten de variabelen in een lijst staan.
voorbeeld voor de functie aggregate() in R met Som:
laten we de functie aggregate() in R gebruiken om de som van alle metrics voor soorten en groepen per soort te maken.
# Aggregate function in R with sum summary statisticsagg_sum = aggregate(iris,by=list(iris$Species),FUN=sum, na.rm=TRUE)agg_sum
wanneer we de bovenstaande code uitvoeren, zal de uitvoer

voorbeeld voor de functie aggregate() in R met telling:
laten we de functie aggregate() gebruiken om de telling van alle metrics tussen soorten en groepen per soort te maken.
# Aggregate function in R with countagg_count = aggregate(iris,by=list(iris$Species),FUN=length)agg_count
de bovenstaande code neemt de eerste 4 kolommen van irisgegevensverzameling en groepen per “soort” door de telling voor elke groep te berekenen, zodat de output
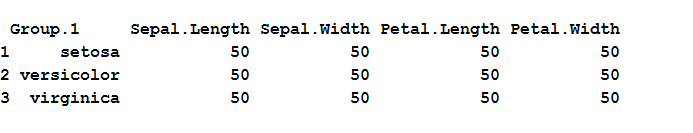
voorbeeld voor de functie aggregate () in R met maximum:
laten we de functie aggregate () gebruiken om het maximum van alle metrics tussen soorten en groepen per soort te creëren.
# Aggregate function in R with maximumagg_max = aggregate(iris,by=list(iris$Species),FUN=max, na.rm=TRUE)agg_max
de bovenstaande code neemt de eerste 4 kolommen van irisgegevensverzameling en groepen per “soort” door berekening van de max voor elke groep, zodat de output

voorbeeld voor de functie aggregate () in R met minimum:
laten we de functie aggregate () gebruiken om het minimum van alle metrics voor soorten en groepen per soort te maken.
# Aggregate function in R with minimumagg_min = aggregate(iris,by=list(iris$Species),FUN=min, na.rm=TRUE)agg_min
de bovenstaande code neemt de eerste 4 kolommen van irisgegevensverzameling en groepen per “soort” door berekening van de min voor elke groep, zodat de output
