Belangrijkste Big Data-technologieën die u moet kennen
Big Data-technologieën, het Buzz-woord dat u veel te horen krijgt in de afgelopen dagen. In dit artikel, zullen we de baanbrekende technologieën die Big Data verspreid zijn takken om grotere hoogten te bereiken bespreken.
- Wat is Big Data-technologie?
- soorten Big Data-technologie
- Top Big Data-technologieën
- opkomende Big Data-technologieën
Wat is Big Data-technologie?
Big Data-technologie kan worden gedefinieerd als een Software-Utility die is ontworpen om de informatie te analyseren, te verwerken en te extraheren uit een uiterst complexe en grote datasets die de traditionele Gegevensverwerkingssoftware nooit zou kunnen verwerken.

we hebben Big Data-verwerkingstechnologieën nodig om deze enorme hoeveelheid realtime data te analyseren en conclusies en voorspellingen te formuleren om de risico ‘ s in de toekomst te verminderen.
laten we nu eens kijken naar de categorieën waarin de Big Data-technologieën zijn ingedeeld:
soorten Big Data-technologieën:
Big Data-technologie is hoofdzakelijk ingedeeld in twee typen:
- operationele Big Data-technologieën
- analytische Big Data-technologieën

Ten eerste draait de operationele Big Data om de normale dagelijkse gegevens die we genereren. Dit kunnen de Online transacties, sociale Media, of de gegevens van een bepaalde organisatie enz. U kunt dit zelfs beschouwen als een soort ruwe Data die wordt gebruikt om de analytische Big Data-technologieën te voeden.
enkele voorbeelden van operationele Big Data-technologieën zijn::
- online ticketboekingen, waaronder uw treintickets, vliegtickets, bioscooptickets etc.
- online winkelen dat is uw Amazon, Flipkart, Walmart, Snap deal en nog veel meer.Instagram, Wat is app en nog veel meer.
- gegevens van sociale media sites zoals Facebook, Instagram, what ‘ s app en nog veel meer.
- de werknemersgegevens van elke multinationale onderneming.
laten we hiermee overgaan op de analytische Big Data-technologieën.
analytische Big Data is als de geavanceerde versie van Big Data-technologieën. Het is een beetje complex dan de operationele Big Data. In het kort, analytische big data is waar de werkelijke prestaties deel komt in het beeld en de cruciale real-time zakelijke beslissingen worden gemaakt door het analyseren van de operationele Big Data.
enkele voorbeelden van analytische Big Data-technologieën zijn::

- Stock marketing
- het uitvoeren van ruimtemissies waarbij elk stukje informatie cruciaal is.
- weersvoorspelling informatie.
- medische velden waar de gezondheidstoestand van een bepaalde patiënt kan worden gecontroleerd.
laten we eens kijken naar de belangrijkste Big Data-technologieën die in de IT-industrieën worden gebruikt.
Top Big Data-technologieën
Top big data-technologieën zijn onderverdeeld in 4 velden die als volgt zijn ingedeeld:
- gegevensopslag
- datamining
- gegevensanalyse
- datavisualisatie
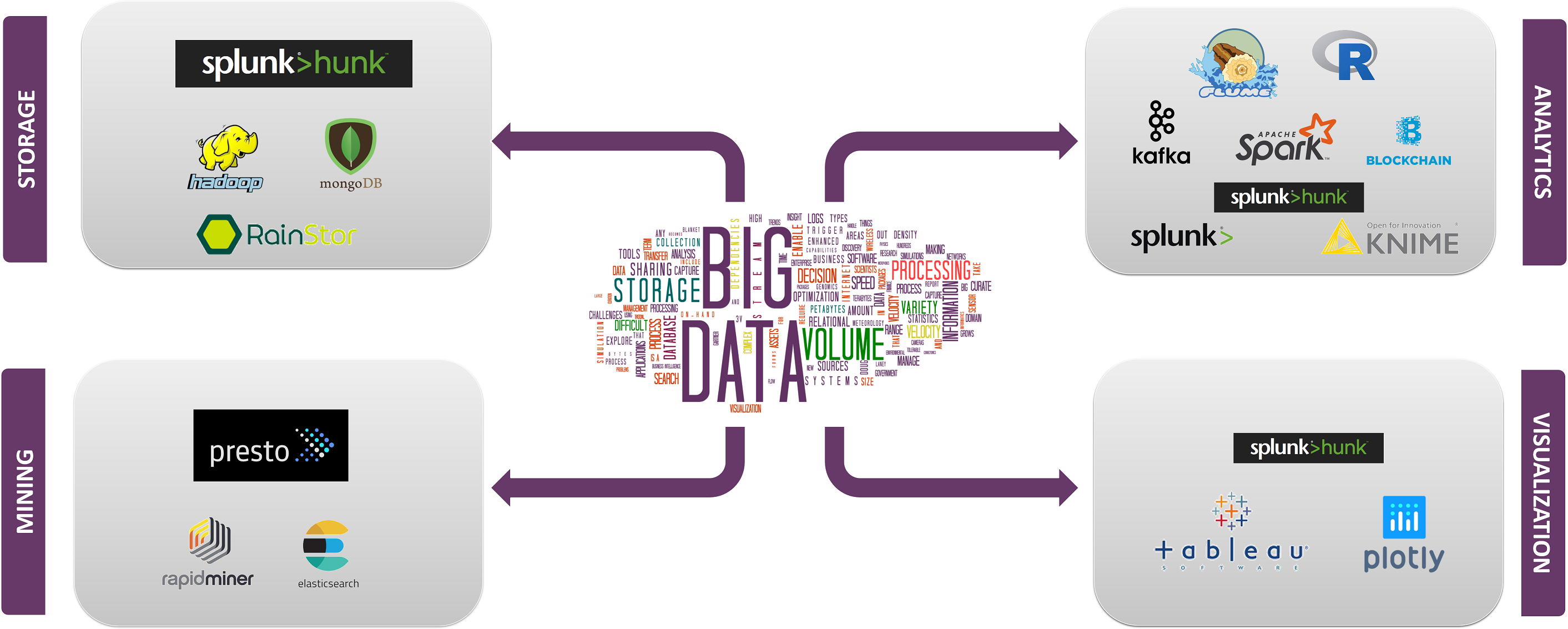
laten we ons nu bezighouden met de technologieën die onder elk van deze categorieën vallen, met hun feiten en mogelijkheden, samen met de bedrijven die ze gebruiken.
laten we beginnen met Big Data-technologieën in Data-opslag.
gegevensopslag
Hadoop
![]()
Hadoop Framework is ontworpen om gegevens op te slaan en te verwerken in een gedistribueerde gegevensverwerking omgeving met commodity hardware met een eenvoudig programmeermodel. Het kan de gegevens in verschillende machines met hoge snelheden en lage kosten opslaan en analyseren.
-
-
-
-
- ontwikkeld door: Apache Software Foundation in het jaar 2011 10 Dec.
- geschreven in: JAVA
- huidige stabiele versie: Hadoop 3.11
-
-
-
bedrijven die Hadoop gebruiken:
MongoDB

de NoSQL Document Databases zoals MongoDB, bieden een direct alternatief voor het rigide schema gebruikt in relationele Databases. Dit maakt MongoDB om flexibiliteit te bieden, terwijl de behandeling van een breed scala aan Datatypes op grote volumes en over gedistribueerde architecturen.
-
-
-
-
- ontwikkeld door: MongoDB in het jaar 2009 11th of Feb
- geschreven in: C++, Go, JavaScript, Python
- huidige stabiele versie: MongoDB 4.0.10
-
-
-
bedrijven die MongoDB gebruiken:

Rainstor
![]() RainStor is een softwarebedrijf dat een databasebeheersysteem met dezelfde naam heeft ontwikkeld voor het beheren en analyseren van Big Data voor grote ondernemingen. Het maakt gebruik van deduplicatie technieken om het proces van het opslaan van grote hoeveelheden gegevens voor referentie te organiseren.
RainStor is een softwarebedrijf dat een databasebeheersysteem met dezelfde naam heeft ontwikkeld voor het beheren en analyseren van Big Data voor grote ondernemingen. Het maakt gebruik van deduplicatie technieken om het proces van het opslaan van grote hoeveelheden gegevens voor referentie te organiseren.
-
-
-
-
- ontwikkeld door: Rainstor Software company in het jaar 2004.
- werkt als: SQL
- huidige stabiele versie: RainStor 5.5
-
-
-
bedrijven die RainStor gebruiken:

Hunk

Hunk kunt u toegang tot gegevens in remote Hadoop Clusters via virtuele indexen en kunt u gebruik maken van de Splunk Search Processing Language om uw gegevens te analyseren. Met Hunk, u kunt rapporteren en visualiseren grote hoeveelheden van uw Hadoop en NoSQL gegevensbronnen.
-
-
-
-
- ontwikkeld door: Splunk INC in het jaar 2013.
- geschreven in: JAVA
- huidige stabiele versie: Splunk Hunk 6.2
-
-
-
laten we nu overgaan op Big Data-technologieën die worden gebruikt in datamining.
datamining
Presto

Presto is een open source gedistribueerde SQL-Query-Engine voor het uitvoeren van interactieve analytische query ‘ s tegen gegevensbronnen van alle groottes, variërend van Gigabytes tot Petabytes. Presto staat querying gegevens in Hive, Cassandra, relationele Databases en propriëtaire gegevensopslag toe.
-
-
-
-
- ontwikkeld door: Apache Foundation in het jaar 2013.
- geschreven in: JAVA
- huidige stabiele versie: Presto 0.22
-
-
-
bedrijven die Presto gebruiken:

snelle mijnwerker
![]()
RapidMiner is een gecentraliseerde oplossing die een zeer krachtige en robuuste grafische gebruikersinterface die gebruikers in staat stelt om te maken, leveren en onderhouden voorspellende Analytics beschikt. Het maakt het mogelijk om zeer geavanceerde Workflows, Scripting ondersteuning in verschillende talen.
-
-
-
-
- ontwikkeld door: RapidMiner in het jaar 2001
- Geschreven in JAVA
- Huidige stabiele versie: RapidMiner 9.2
-
-
-
Bedrijven die Gebruik maken van RapidMiner:

Elasticsearch
![]()
Elasticsearch is een zoekmachine gebaseerd op de Lucene Bibliotheek. Het biedt een gedistribueerde, MultiTenant-staat, Full-Text zoekmachine met een HTTP webinterface en Schema-vrije JSON documenten.
-
-
-
-
- ontwikkeld door: Elastic NV in het jaar 2012.
- geschreven in: JAVA
- huidige stabiele versie: ElasticSearch 7.1
-
-
-
bedrijven die Elasticsearch gebruiken:

hiermee kunnen we nu overstappen op Big Data-technologieën die worden gebruikt in Data-analyse.
gegevensanalyse
Kafka

Apache Kafka is een gedistribueerd Streaming platform. Een streaming platform heeft drie belangrijke mogelijkheden die als volgt zijn:
-
-
-
-
- uitgever
- abonnee
- Consumer
-
-
-
dit is vergelijkbaar met een Message Queue of een Enterprise Messaging systeem.
- ontwikkeld door: Apache Software Foundation in het jaar 2011
- geschreven in: Scala, JAVA
- huidige stabiele versie: Apache Kafka 2.2.0
bedrijven die Kafka gebruiken:

Splunk
 Splunk vangt, indexeert en correleert Real-time gegevens in een doorzoekbare Repository van waaruit het grafieken, rapporten, waarschuwingen, Dashboards en datavisualisaties kan genereren. Het wordt ook gebruikt voor applicatiebeheer, beveiliging en Compliance, evenals Business en Web Analytics.
Splunk vangt, indexeert en correleert Real-time gegevens in een doorzoekbare Repository van waaruit het grafieken, rapporten, waarschuwingen, Dashboards en datavisualisaties kan genereren. Het wordt ook gebruikt voor applicatiebeheer, beveiliging en Compliance, evenals Business en Web Analytics.
-
-
-
-
- ontwikkeld door: Splunk INC in het jaar 2014 6 mei
- geschreven in: Ajax, C++, Python, XML
- huidige stabiele versie: Splunk 7.3
-
-
-
bedrijven die Splunk gebruiken:

KNIME
 KNIME stelt gebruikers in staat om visueel gegevensstromen te creëren, selectief enkele of alle Analysestappen uit te voeren en de resultaten, modellen en interactieve weergaven te inspecteren. KNIME is geschreven in Java en gebaseerd op Eclipse en maakt gebruik van de extensie mechanisme toe te voegen Plugins die extra functionaliteit.
KNIME stelt gebruikers in staat om visueel gegevensstromen te creëren, selectief enkele of alle Analysestappen uit te voeren en de resultaten, modellen en interactieve weergaven te inspecteren. KNIME is geschreven in Java en gebaseerd op Eclipse en maakt gebruik van de extensie mechanisme toe te voegen Plugins die extra functionaliteit.
-
-
-
-
- ontwikkeld door: KNIME in het jaar 2008
- geschreven in: JAVA
- huidige stabiele versie: KNIME 3.7.2
-
-
-
bedrijven die KNIME gebruiken:
 Vonk
Vonk

Spark biedt in-Memory Computing mogelijkheden om snelheid te leveren, een gegeneraliseerde uitvoering Model ter ondersteuning van een breed scala aan toepassingen, en Java, Scala en Python API ‘ s voor het gemak van ontwikkeling.
-
-
-
-
- ontwikkeld door: Apache Software Foundation
- geschreven in: Java, Scala, Python, R
- huidige stabiele versie: Apache Spark 2.4.3
-
-
-
bedrijven die Spark gebruiken:

R-taal

R is een programmeertaal en vrije software-omgeving voor statistische Computing en grafieken. De R taal wordt veel gebruikt onder statistici en data Miners voor het ontwikkelen van statistische Software en majorly in Data-analyse.
-
-
-
-
- ontwikkeld door: R-Foundation in het jaar 2000 29 Feb
- geschreven in: Fortran
- huidige stabiele versie: R-3.6.0
-
-
-
bedrijven die R-taal gebruiken:

Blockchain
![]() BlockChain wordt gebruikt in essentiële functies zoals betaling, escrow en titel kan ook fraude verminderen, de financiële privacy verhogen, transacties versnellen en markten internationaliseren.
BlockChain wordt gebruikt in essentiële functies zoals betaling, escrow en titel kan ook fraude verminderen, de financiële privacy verhogen, transacties versnellen en markten internationaliseren.
BlockChain kan worden gebruikt om het volgende te bereiken in een zakelijke netwerkomgeving:
-
-
-
-
- gedeeld grootboek: Hier kunnen we het gedistribueerde systeem van records toevoegen over een zakelijk netwerk.
- Smart Contract: Zakelijke voorwaarden zijn opgenomen in de transactiedatabase en worden uitgevoerd met transacties.
- Privacy: zorgen voor de juiste zichtbaarheid, transacties zijn veilig, geverifieerd en verifieerbaar
- Consensus: alle partijen in een zakelijk netwerk stemmen in met netwerk geverifieerde transacties.
-
-
-
- ontwikkeld door: Bitcoin
- geschreven in: JavaScript, C++, Python
- huidige stabiele versie: Blockchain 4.0
bedrijven die Blockchain gebruiken:

hiermee gaan we over op data visualisatie Big Data-technologieën
Data visualisatie
Tableau

Tableau is een krachtige en snelst groeiende data visualisatie tool gebruikt in de Business Intelligence-industrie. Data-analyse is zeer snel met Tableau en de visualisaties gemaakt zijn in de vorm van Dashboards en werkbladen.
-
-
-
-
- ontwikkeld door: TableAU 2013 17 mei
- geschreven in: JAVA, C++, Python, C
- huidige stabiele versie: TableAU 8.2
-
-
-
bedrijven die Tableau gebruiken:

Plotly
![]()
voornamelijk gebruikt om het maken van grafieken sneller en efficiënter te maken. API bibliotheken voor Python, R, MATLAB, Node.js, Julia, en Arduino en een REST API. Plotly kan ook worden gebruikt om interactieve grafieken met Jupyter notebook stijl.
-
-
-
-
- ontwikkeld door: Plotly in het jaar 2012
- geschreven in: JavaScript
- huidige stabiele versie: Plotly 1.47.4
-
-
-
bedrijven die Plotly gebruiken:
 nu bespreken we de opkomende Big Data-technologieën
nu bespreken we de opkomende Big Data-technologieën
opkomende Big Data-technologieën
TensorFlow

TensorFlow heeft een uitgebreid, flexibel ecosysteem van tools, Bibliotheken en Community resources waarmee onderzoekers de state-of-the-art in Machine Learning kunnen pushen en ontwikkelaars gemakkelijk Machine Learning-aangedreven applicaties kunnen bouwen en implementeren.
-
-
-
-
- ontwikkeld door: Google Brain Team in het jaar 2019
- geschreven in: Python, C++, CUDA
- huidige stabiele versie: TensorFlow 2.0 beta
-
-
-
bedrijven die TensorFlow gebruiken:

Beam
![]()
Apache Beam biedt een draagbare API-laag voor het bouwen van geavanceerde parallelle gegevensverwerking pijpleidingen die kunnen worden uitgevoerd in een verscheidenheid van uitvoering motoren of Runners.
-
-
-
-
- ontwikkeld door: Apache Software Foundation in het jaar 2016 15 juni
- geschreven in: JAVA, Python
- huidige stabiele versie: Apache Beam 0.1.0 incubating.
-
-
-
bedrijven die Beam gebruiken:
 Docker
Docker

Docker is een tool die is ontworpen om het gemakkelijker te maken om applicaties te maken, te implementeren en uit te voeren met behulp van Containers. Met Containers kan een ontwikkelaar een applicatie verpakken met alle onderdelen die hij nodig heeft, zoals bibliotheken en andere afhankelijkheden, en het allemaal als één pakket verzenden.
-
-
-
-
- ontwikkeld door: Docker INC in het jaar 2003 13 maart.
- geschreven in: Go
- huidige stabiele versie: Docker 18.09
-
-
-
bedrijven die Docker gebruiken:

Airflow
![]() Apache Airflow is een workflow-automatiserings-en planningsysteem dat kan worden gebruikt voor het schrijven en beheren van Datapijpleidingen. Airflow maakt gebruik van workflows gemaakt van gerichte acyclische grafieken (DAGs) van taken. Het definiëren van Workflows in code zorgt voor eenvoudiger onderhoud, testen en versiebeheer.
Apache Airflow is een workflow-automatiserings-en planningsysteem dat kan worden gebruikt voor het schrijven en beheren van Datapijpleidingen. Airflow maakt gebruik van workflows gemaakt van gerichte acyclische grafieken (DAGs) van taken. Het definiëren van Workflows in code zorgt voor eenvoudiger onderhoud, testen en versiebeheer.
-
-
-
-
- Ontwikkeld door: Apache Software Foundation is op 15 Mei 2019
- , Geschreven in Python
- Huidige stabiele versie: Apache Luchtstroom 1.10.3
-
-
-
Bedrijven die Gebruik maken van de Luchtstroom:

Kubernetes
 Kubernetes is een Leverancier-Onafhankelijke Cluster en Container Management tool, Open Afkomstig van Google in 2014. Het biedt een platform voor automatisering, implementatie, schalen en bewerkingen van Applicatiecontainers in Clusters van Hosts.
Kubernetes is een Leverancier-Onafhankelijke Cluster en Container Management tool, Open Afkomstig van Google in 2014. Het biedt een platform voor automatisering, implementatie, schalen en bewerkingen van Applicatiecontainers in Clusters van Hosts.
-
-
-
-
- Ontwikkeld door: Cloud Native Computing Foundation in het jaar 2015 21 juli
- Geschreven in: Ga naar
- Huidige stabiele versie: Kubernetes 1.14
-
-
-
Bedrijven die Gebruik maken van Kubernetes:

Met deze, we komen tot een einde van dit artikel. Ik hoop dat ik wat licht heb geworpen op uw kennis over Big Data en haar technologieën.
nu U Big data en haar technologieën hebt begrepen, kunt u de Hadoop training van Edureka bekijken, een vertrouwd online leerbedrijf met een netwerk van meer dan 250.000 tevreden leerlingen verspreid over de hele wereld. De Edureka Big Data Hadoop Certificering Training helpt leerlingen worden expert in HDFS, garen, MapReduce, Pig, Hive, HBase, Oozie, Flume en Sqoop met behulp van real-time use cases op Retail, sociale Media, luchtvaart, toerisme, Financiën domein.