KDnuggets
Door Sydney Firmin, Alteryx.
“in wezen zijn alle modellen verkeerd, maar sommige modellen zijn nuttig.”- George Box
dit beroemde citaat van George Box werd voor het eerst opgenomen in 1976 in de paper “Science and Statistics”, gepubliceerd in het Journal of the American Statistical Association. Het is een belangrijk citaat op het gebied van statistieken en analytische modellen en kan in twee delen worden uitgepakt.
Alle modellen zijn verkeerd
om in deze statement te graven, moeten we definiëren en onderzoeken wat een model is.
in de context van dit artikel kan een model worden gezien als een vereenvoudigde weergave van een systeem of object. Statistische modellen benaderen patronen in een dataset door aannames te maken over de gegevens en de omgeving waarin deze werden verzameld en toegepast.
de drie brede categorieën aannames die door statistische modellen worden gemaakt, zijn verdelingsaannamen (aannames over de verdeling van waarden in een variabele of de verdeling van waarnemingsfouten), structurele aannames (aannames over de functionele relatie tussen variabelen) en cross-variation aannames (gezamenlijke kansverdeling).
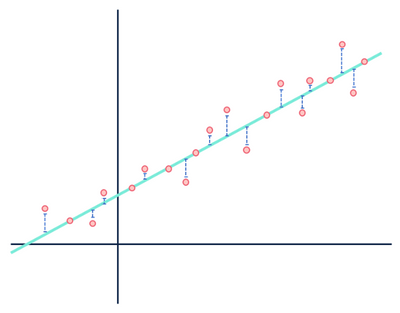
een lineair regressiemodel gaat er bijvoorbeeld van uit dat de relaties tussen variabelen in een gegevensverzameling lineair (en alleen lineair) zijn. In de ogen van een lineair model, Elke afstand tussen de waarnemingen die deel uitmaken van de dataset en de gemodelleerde lijn is gewoon ruis (dat wil zeggen, willekeurige of onverklaarbare fluctuaties in de gegevens) en kan uiteindelijk worden genegeerd.
let niet op de afstanden in het blauw.
George Box verklaarde dat alle modellen specifiek in de context van statistische modellen verkeerd zijn. Omdat de aard van een model een vereenvoudigde en geïdealiseerde representatie van iets is, zullen alle modellen in zekere zin verkeerd zijn. Modellen zullen nooit “de waarheid” zijn als waarheid volledig representatief voor de werkelijkheid betekent. Het is van groot belang om rekening te houden met de veronderstellingen die zijn gemaakt bij het genereren van een model, omdat modellen pas echt nuttig zijn wanneer de veronderstellingen worden opgehouden.
kaarten en miniaturen
soortgelijke waarnemingen met Box ‘ s “all models are wrong” zijn op veel verschillende gebieden aanwezig.
er is een aforisme dat verwijst naar de kaart-territoriumrelatie, toegeschreven aan Alfred Korzybski:
een kaart is niet het grondgebied dat het vertegenwoordigt, maar heeft, indien correct, een soortgelijke structuur als het grondgebied, wat het nut ervan verklaart.
kaarten zijn nuttig omdat ze abstracties zijn van een echt object op een meer beheersbare schaal, maar ze zullen altijd een bepaald detailniveau uitsluiten. Afhankelijk van hoeveel oppervlakte een kaart omvat, kan er ook enige vervorming zijn als gevolg van de projectie van de kaart (veroorzaakt door het lastige proces van het omzetten van een bolvormige naar een platte weergave).
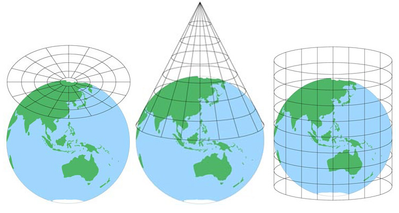
(beeldbron.)
de enige echt nauwkeurige kaart zou een 1:1 replicatie zijn van het gebied dat het vertegenwoordigt. Een dergelijke kaart zou echter niet nuttiger zijn dan door het gebied zelf te navigeren.
beschouw het citaat van dichter Paul Valery:
alles simpel is vals. Alles wat complex is, is onbruikbaar.Bonini ‘ s Paradox, genoemd naar een professor in het bedrijfsleven van Stanford, beschrijft de uitdaging van het creëren van bruikbare, complete modellen of simulaties van complexe systemen. Er is vaak een evenwicht tussen complexiteit en nauwkeurigheid in modelontwikkeling. Als het doel van een model is om een relatie of systeem duidelijker te maken, verslaat toegevoegde complexiteit dat doel (hoewel het het model nauwkeuriger zou kunnen maken).
op een hoog niveau beschrijft de kaart-Territorium relatie ook de relatie tussen een object en een representatie van het object.
als je ooit een les filosofie hebt gevolgd, ben je misschien het werk The Treachery of Images van de surrealistische kunstenaar Rene Magritte tegengekomen.
de tekst vertaalt naar ” Dit is geen pijp.”En dat is het niet. We kunnen dit (digitale) beeld niet volproppen met tabak en het roken omdat het gewoon een representatie is van een echt object.
modellen zijn abstracties. Net als kaarten, of miniatuur architectonische modellen, of schema ‘ s, kunnen ze niet elk detail vastleggen van het object of systeem waarop ze zijn gebaseerd, al was het maar omdat ze niet bestaan in de echte wereld en niet op dezelfde manier functioneren.
Als Alle Modellen Verkeerd Zijn, Waarom De Moeite?George Box ‘ aforisme is niet zonder zijn critici.
het probleem dat veel statistici met dit citaat hebben lijkt in grote lijnen in twee categorieën te vallen:
- modellen die het mis hebben is een voor de hand liggende verklaring. Natuurlijk zijn alle modellen verkeerd, het zijn modellen.
- dit citaat wordt gebruikt als excuus voor slechte modellen.
statisticus J. Michael Steele was kritisch over het adagium (zie dit persoonlijke essay). Steele ‘ s primaire argument is dat “verkeerd” alleen in het spel komt als het model de vraag die het beweert te beantwoorden niet correct beantwoordt (bijv., dat een gebouw op een kaart verkeerd is gelabeld, niet dat het gebouw wordt weergegeven door een klein vierkant). Steele gaat naar state:
de meerderheid van de gepubliceerde statistische methoden hunkeren naar een eerlijk voorbeeld.
Steele stelt dat statistische modellen vaak niet geschikt zijn voor een adequate geschiktheidsmaatstaf, en dat veel door statistici ontwikkelde modellen niet volstaan voor de beoogde gebruiksgevallen.
in het artikel statistiek als wetenschap, geen kunst: The Way to Survive in Data Science, Mark Van der Laan (Statistics at UC Berkeley) attributeert de box quote als een bijdragende oorzaak van slechte statistische modellen en verwerpt het als “complete onzin.”Hij gaat verder met schrijven:
de basis van de statistiek ( … ) kon niet zijn geweest om willekeurig een “handig” statistisch model te kiezen. Dat is echter precies wat de meeste statistici onbezonnen doen, trots verwijzend naar het citaat: “Alle modellen zijn verkeerd, maar sommige zijn nuttig.”Hierdoor zijn modellen die zo onrealistisch zijn dat ze geïndexeerd zijn door een eindige dimensionale parameter nog steeds de status quo, hoewel iedereen het erover eens is dat ze vals zijn.
als oplossing roept Van der Laan statistici op te stoppen met het gebruik van Box ‘ s quote en zich ertoe te verbinden gegevens, statistieken en de wetenschappelijke methode serieus te nemen. Hij roept statistici op om tijd te besteden aan het leren hoe gegevens in een gegeven dataset werden gegenereerd en zich te committeren aan het ontwikkelen van realistische statistische modellen met behulp van machine learning en data-adaptieve schattingstechnieken over meer traditionele parametrische modellen.
dit artikel bevat reacties van statistici Michael Lavine en Christopher Tong, evenals een reactie op de reacties van de oorspronkelijke auteur. De twee weerleggende statistici wijzen op voorbeelden waarbij modellen waarvan bekend is dat ze verkeerd zijn, maar vaak worden gebruikt omdat ze nuttig zijn en geschikt zijn voor een bepaald probleem. Hun voorbeelden omvatten de drie verschillende modellen van licht gevonden op het gebied van de optica (geometrische optica, fysische optica, en kwantum optica; alle drie modellen vertegenwoordigen licht anders, zijn “verkeerd” in zekere zin, en worden nog steeds gebruikt vandaag), en de (bijna) lineaire relatie tussen de log van koolstofflux en bodemtemperatuur gevonden in gegevens verzameld in de Harvard Forest.
op zijn beurt reageert Van der Laan op deze voorbeelden en andere kritiek op zijn artikel, in het bijzonder op zijn concept van het vinden van een “waar” model. De response letters zijn zeker de moeite waard om te lezen als je geïnteresseerd bent. Dit is een actief debat op het gebied van statistiek en Data science.
maar sommige modellen zijn nuttig
ondanks de beperkingen van modellen kunnen veel modellen zeer nuttig zijn. Omdat ze vereenvoudigd zijn, zijn modellen vaak nuttig bij het begrijpen van een bepaalde component of facet van een systeem.
in de context van data science kunnen machine learning en statistische modellen nuttig zijn om onbekende waarden te schatten (voorspellen). In veel contexten kan, als de veronderstellingen van het model standhouden, een onzekere schatting die door een sterk statistisch model wordt verstrekt, nog steeds zeer nuttig zijn voor het nemen van beslissingen.
de tweede, minder geciteerde helft van George Box ‘ s wijsheid is dit:
“de praktische vraag is hoe verkeerd (modellen) moeten zijn om niet nuttig te zijn.”- George Box
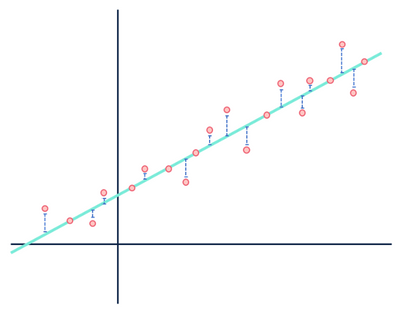
laten we nog eens kijken naar onze Lineaire regressie voorbeeld:
Meestal heb ik teveel tijd besteed aan dit beeld om het maar één keer te gebruiken.
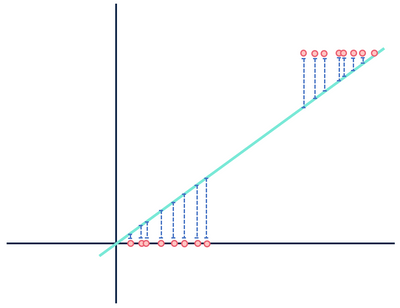
laten we nu eens kijken naar een ander theoretisch lineair regressiemodel dat past bij een andere dataset.
let niet op de afstanden… wacht dit kan niet goed zijn.
beide cijfers tonen een fout, maar de ene gegevensverzameling toont een duidelijk lineair verband, terwijl de andere logistisch is. Beide modellen zijn “verkeerd”, maar de ene vangt duidelijk een echte relatie tussen variabelen, terwijl de andere dat niet doet, waardoor de ene nuttig is en de andere nutteloos. Het weggooien van de afstanden in blauw als ruis is redelijk als de gegevens een lineaire relatie hebben, maar deze veronderstelling valt uiteen wanneer de relatie een andere functionele vorm heeft dan het door u gekozen model.
het maken van goede modellen
het feit dat modellen verkeerd zijn of beperkt in de reikwijdte van wat ze vertegenwoordigen lijkt voor veel mensen die met modellen werken voor de hand liggend, maar helaas beseffen veel mensen dit niet of denken er veel over na. Daarom vind ik het belangrijk om de woorden van George Box in gedachten te houden bij het ontwikkelen van een model. Het mag niet worden gebruikt als een excuus om slechte modellen te bouwen.
voor meer informatie, Steele heeft een aantal grote klasse noten: heeft het Model zin? en heeft het Model zin? Deel II: benutting van de toereikendheid. Een andere grote bron is de paper ‘ All models are wrong…’: een inleiding tot modelonzekerheid van een modelselectie workshop die in 2011 in Groningen werd gehouden.
een andere interessante lezing is wanneer alle modellen verkeerd zijn ten opzichte van kwesties in wetenschap en technologie, waarin Box ‘ s woorden worden gebruikt als een oproep tot meer transparantie in wetenschappelijke en statistische modellen.
het belangrijkste om van dit alles af te nemen is ervoor te zorgen dat u begrijpt welke aspecten van uw gegevens door uw model worden vastgelegd en welke niet. Het is van cruciaal belang om uw aannames en uitgangspunten te controleren. Als statisticus of Data scientist is het uw verantwoordelijkheid om rigoureuze modellen te produceren en hun beperkingen te kennen. Meld altijd uw onzekerheid en de scope van uw model. Met dat in het achterhoofd, zult u in staat om modellen die, hoewel mogelijk verkeerd, kan zeker nuttig zijn.
oorspronkelijk. Opnieuw geplaatst met toestemming.
Bio: Een geograaf door training en een data geek in hart en nieren, Sydney is ervan overtuigd dat gegevens en kennis zijn het meest waardevol wanneer ze duidelijk kunnen worden gecommuniceerd en begrepen. In haar huidige rol als SR.Data Science Content Engineer brengt ze haar dagen door met doen waar ze het meest van houdt; het transformeren van technische kennis en onderzoek naar boeiende, creatieve en leuke content voor de Alteryx Community.
gerelateerd:
- de 3 grootste fouten bij het leren van Data Science
- 3 grote problemen met Big Data en hoe ze op te lossen
- kiezen tussen Modelkandidaten