KDnuggets
By Sydney Firmin, Alteryx.
„zasadniczo wszystkie modele są błędne, ale niektóre modele są użyteczne.”- George Box
ten słynny cytat George 'a Box’ a został po raz pierwszy odnotowany w 1976 roku w artykule „Science and Statistics”, opublikowanym w Journal of the American Statistical Association. Jest to ważny cytat z dziedziny statystyki i modeli analitycznych i może być rozpakowany w dwóch częściach.
wszystkie modele są błędne
aby zagłębić się w to stwierdzenie, musimy zdefiniować i zbadać, czym jest model.
w kontekście tego artykułu model można traktować jako uproszczoną reprezentację systemu lub obiektu. Modele statystyczne przybliżają wzorce w zbiorze danych, przyjmując założenia dotyczące danych, a także środowiska, w którym zostały zebrane i zastosowane.
trzy szerokie kategorie założeń dokonanych przez modele statystyczne są założenia dystrybucyjne (założenia dotyczące rozkładu wartości w zmiennej lub rozkładu błędów obserwacyjnych), założenia strukturalne (założenia dotyczące zależności funkcjonalnej między zmiennymi) i założenia zmienności krzyżowej (wspólny rozkład prawdopodobieństwa).
na przykład model regresji liniowej zakłada, że relacje między zmiennymi w zbiorze danych są liniowe (i tylko liniowe). W oczach modelu liniowego, każda odległość między obserwacjami, które składają się na zestaw danych i modelowanej linii jest tylko szum (to znaczy, losowe lub niewyjaśnione wahania w danych) i ostatecznie może być ignorowane.
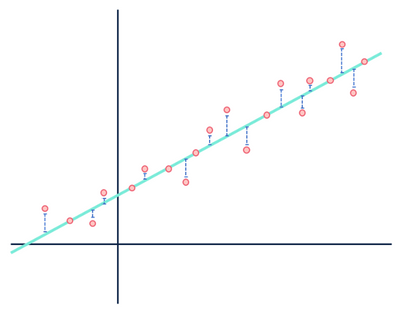
nie zwracaj uwagi na odległości w Kolorze Niebieskim.
George Box stwierdził, że wszystkie modele są błędne szczególnie w kontekście modeli statystycznych. Ponieważ sama natura modelu jest uproszczoną i wyidealizowaną reprezentacją czegoś, wszystkie modele będą w pewnym sensie błędne. Modele nigdy nie będą „prawdą”, jeśli prawda oznacza całkowicie reprezentację rzeczywistości. Bardzo ważne jest, aby wziąć pod uwagę założenia przyjęte podczas generowania modelu, ponieważ modele są naprawdę pomocne tylko wtedy, gdy założenia są podtrzymywane.
Mapy i miniatury
podobne obserwacje do „wszystkie modele są błędne” Box ’ a są obecne w wielu różnych dziedzinach.
istnieje aforyzm nawiązujący do relacji mapa-terytorium, przypisywany Alfredowi Korzybskiemu:
mapa nie jest terytorium, które reprezentuje, ale, jeśli jest poprawna, ma podobną strukturę do terytorium, co stanowi o jego przydatności.
mapy są użyteczne, ponieważ są abstrakcjami rzeczywistego obiektu w łatwiejszej do opanowania skali, ale zawsze wykluczają pewien poziom szczegółowości. W zależności od tego, ile powierzchni obejmuje Mapa, mogą wystąpić pewne zniekształcenia spowodowane rzutowaniem mapy (spowodowane trudnym procesem przekształcania sferycznego globu w płaską reprezentację).
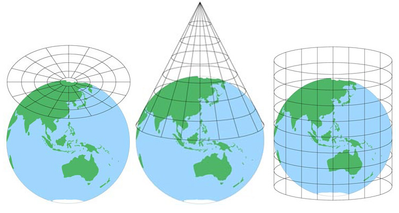
(źródło obrazu.)
jedyną naprawdę dokładną mapą byłoby odwzorowanie terytorium, które reprezentuje w stosunku 1: 1. Jednak taka mapa nie byłaby bardziej pomocna niż nawigacja po samym terytorium.
rozważ cytat z poety Pawła Walerego:
wszystko, co proste, jest fałszywe. Wszystko, co jest złożone, jest bezużyteczne.
nazwany na cześć profesora Stanford business, paradoks Boniniego opisuje wyzwanie tworzenia użytecznych, kompletnych modeli lub symulacji złożonych systemów. Często istnieje balansowanie między złożonością a dokładnością w opracowywaniu modeli. Jeśli celem modelu jest uczynienie relacji lub systemu jaśniejszym, dodana złożoność podważa ten cel (chociaż może sprawić, że model będzie dokładniejszy).
na wysokim poziomie relacja mapa-terytorium opisuje również relację między obiektem a reprezentacją obiektu.
jeśli kiedykolwiek chodziłeś na zajęcia z filozofii, być może natknąłeś się na dzieło Zdrada obrazów autorstwa surrealistycznego artysty Rene Magritte.

tekst tłumaczy się na ” to nie jest rura.”I nie jest. Nie możemy wypychać tego (cyfrowego) obrazu tytoniem i palić go, ponieważ jest to tylko reprezentacja prawdziwego obiektu.
modele to abstrakcje. Podobnie jak mapy, miniaturowe modele architektoniczne czy schematy, nie mogą uchwycić każdego szczegółu obiektu lub systemu, na którym są oparte, choćby dlatego, że nie istnieją w świecie rzeczywistym i nie funkcjonują w ten sam sposób.

Jeśli Wszystkie Modelki Się Mylą, Po Co Się Męczyć?
aforyzm George 'a Box’ a nie jest bez krytyków.
problem wielu statystyków z tym cytatem wydaje się zasadniczo podzielić na dwie kategorie:
- mylenie się modeli jest oczywistym stwierdzeniem. Oczywiście Wszystkie modelki się mylą, są modelkami.
- ten cytat jest używany jako pretekst do złych modeli.
statystyk J. Michael Steele krytycznie ocenił powiedzenie (zobacz ten esej osobisty). Głównym argumentem Steele ’ a jest to, że „źle” wchodzi w grę tylko wtedy, gdy model nie odpowiada poprawnie na pytanie, na które twierdzi, że odpowiada (np., że budynek na mapie jest źle oznaczony, a nie że budynek jest reprezentowany przez mały kwadrat). Steele idzie na stan:
większość opublikowanych metod statystycznych głosi jeden uczciwy przykład.
Steele twierdzi, że modele statystyczne często nie są wystarczające do odpowiedniej miary sprawności, a wiele modeli opracowanych przez statystyków nie wystarcza do ich zamierzonego zastosowania.
w artykule Statystyka jako nauka, nie Sztuka: The Way To Survive in Data Science, Mark van der Laan (Statistics at UC Berkeley) przypisuje cytat z pudełka jako przyczynę złych modeli statystycznych i odrzuca go jako ” kompletny nonsens.”Pisze dalej:
podstawą statystyki ( … ) nie mógł być arbitralny wybór „wygodnego” modelu statystycznego. Jednak właśnie to robi większość statystyków, dumnie odwołując się do cytatu: „wszystkie modele są błędne, ale niektóre są użyteczne.”Z tego powodu modele, które są tak nierealistyczne, że są indeksowane przez skończony parametr wymiarowy, nadal stanowią status quo, chociaż wszyscy zgadzają się, że są one znane jako fałszywe.
jako rozwiązanie Van der Laan wzywa statystyków do zaprzestania korzystania z cytatu Box ’ a i podjęcia zobowiązania do poważnego potraktowania danych, statystyk i metody naukowej. Wzywa on statystyków, aby poświęcili czas na naukę, w jaki sposób dane w danym zbiorze danych zostały wygenerowane i zobowiązali się do opracowania realistycznych modeli statystycznych z wykorzystaniem uczenia maszynowego i technik estymacji adaptacyjnej danych w porównaniu z bardziej tradycyjnymi modelami parametrycznymi.
Ten artykuł zawiera odpowiedzi statystyków Michaela Lavine i Christophera Tonga, a także odpowiedź na odpowiedzi oryginalnego autora. Dwóch obalających statystyków wskazuje na przykłady, w których modele są znane jako błędne, ale często są stosowane, ponieważ są użyteczne i pasują do danego problemu. Ich przykłady obejmują trzy różne modele światła Znalezione w dziedzinie optyki (Optyka geometryczna, Optyka fizyczna i optyka kwantowa; wszystkie trzy modele reprezentują światło inaczej, są w pewnym sensie „błędne” i są nadal stosowane do dziś) oraz (prawie) liniową zależność między logiem strumienia węgla a temperaturą gleby znalezioną w danych zebranych w lesie Harvarda.
z kolei Van der Laan odpowiada na te przykłady i inne krytyki swojego artykułu, w szczególności na jego koncepcję znalezienia „prawdziwego” modelu. Listy odpowiedzi są zdecydowanie warte przeczytania, jeśli jesteś zainteresowany. Stanowi to aktywny obszar debaty w dziedzinie statystyki i Nauk o danych.
ale niektóre modele są przydatne
pomimo ograniczeń modeli, wiele modeli może być bardzo przydatnych. Ponieważ są one uproszczone, modele są często pomocne w zrozumieniu określonego elementu lub aspektu systemu.
w kontekście nauki o danych, uczenie maszynowe i modele statystyczne mogą być przydatne do szacowania (przewidywania) nieznanych wartości. W wielu kontekstach, jeśli założenia Modelu się utrzymają, niepewne oszacowanie dostarczone przez silny model statystyczny może nadal być bardzo pomocne w podejmowaniu decyzji.
druga, mniej cytowana połowa mądrości George 'a Box’ a to:
„praktyczne pytanie brzmi, jak złe muszą być (modele), aby nie były użyteczne.”- George Box
przyjrzyjmy się jeszcze raz naszemu przykładowi regresji liniowej:
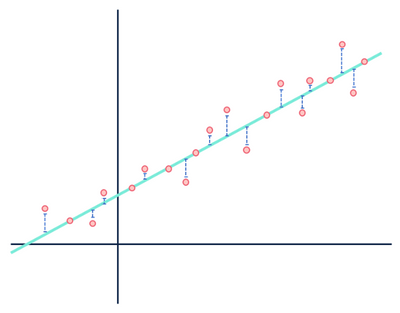
w większości spędziłem zbyt dużo czasu na tym obrazie, aby użyć go tylko raz.
przyjrzyjmy się teraz innemu teoretycznemu modelowi regresji liniowej dopasowanemu do innego zestawu danych.
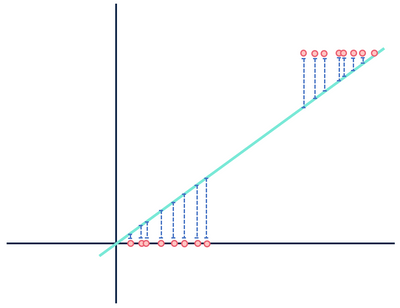
nie zwracaj uwagi na odległości … czekaj, to nie może być prawda.
obie liczby pokazują błąd, ale jeden zestaw danych pokazuje wyraźnie liniową zależność, podczas gdy drugi jest logistyczny. Oba modele są „błędne”, ale jeden wyraźnie oddaje rzeczywistą relację między zmiennymi, podczas gdy drugi nie, czyniąc jeden użytecznym, a drugi bezużytecznym. Odrzucenie odległości na niebiesko jako szumu jest uzasadnione, jeśli dane mają relację liniową, ale to założenie rozpada się, gdy relacja ma inny kształt funkcjonalny niż wybrany model.
tworzenie dobrych modeli
fakt, że modele są błędne lub ograniczone w zakresie tego, co reprezentują, może wydawać się oczywisty dla wielu osób, które pracują z modelami, ale niestety wiele osób nie zdaje sobie z tego sprawy i nie myśli o tym zbyt wiele. Dlatego uważam, że ważne jest, aby przy opracowywaniu modelu pamiętać o słowach George 'a Box’ a. Nie powinno być używane jako pretekst do budowania złych modeli.
do dalszej lektury Steele ma kilka świetnych uwag klasowych: czy Model ma sens? a czy Model ma sens? Część II: wykorzystanie wystarczalności. Kolejnym świetnym źródłem jest artykuł ” All models are wrong…”: wprowadzenie do niepewności modelu z warsztatów wyboru modeli, które odbyły się w 2011 r.w Groningen.
kolejną ciekawą lekturą jest to, że wszystkie modele są błędne z zagadnień Nauki i technologii, co wymaga słów Box jako wezwania do bardziej rygorystycznej przejrzystości w modelach naukowych i statystycznych.
ważną rzeczą, którą należy wziąć z tego wszystkiego, jest upewnienie się, że rozumiesz, jakie aspekty danych są przechwytywane przez twój model, a jakie nie. Ważne jest, aby sprawdzić swoje założenia i punkty wyjścia. Jako statystyk lub analityk danych, Twoim obowiązkiem jest tworzenie rygorystycznych modeli, a także poznanie ich ograniczeń. Zawsze zgłaszaj swoją niepewność, a także zakres swojego modelu. Mając to na uwadze, będziesz w stanie tworzyć modele, które, choć być może błędne, z pewnością mogą być użyteczne.
oryginał. Reposted with permission.
Bio: Jako geograf z wykształcenia i geograf danych w sercu, Sydney mocno wierzy, że dane i wiedza są najcenniejsze, gdy można je jasno przekazać i zrozumieć. W swojej obecnej roli SR. Data Science Content Engineer spędza swoje dni robiąc to, co kocha najbardziej; przekształcając wiedzę techniczną i badania w angażujące, kreatywne i zabawne treści dla społeczności Alteryx.
podobne:
- 3 największe błędy w nauce o danych
- 3 duże problemy z Big Data i jak je rozwiązać
- wybór pomiędzy modelowymi kandydatami