Najlepsze technologie Big Data, które musisz wiedzieć
technologie Big Data, Buzz-słowo, które można usłyszeć wiele w ostatnich dniach. W tym artykule omówimy przełomowe technologie, które sprawiły, że Big Data rozprzestrzenił swoje oddziały na większe wysokości.
- czym jest technologia Big Data?
- rodzaje technologii Big Data
- najlepsze technologie Big Data
- nowe technologie Big Data
czym jest technologia Big Data?
Technologia Big Data może być zdefiniowana jako oprogramowanie-narzędzie, które jest przeznaczone do analizy, przetwarzania i wyodrębniania informacji z niezwykle złożonych i dużych zbiorów danych, z którymi tradycyjne oprogramowanie do przetwarzania danych nigdy nie mogłoby sobie poradzić.

potrzebujemy technologii przetwarzania dużych zbiorów danych, aby analizować tę ogromną ilość danych w czasie rzeczywistym i formułować wnioski i prognozy, aby zmniejszyć ryzyko w przyszłości.
teraz rzućmy okiem na kategorie, w których klasyfikowane są technologie Big Data:
rodzaje technologii Big Data:
Technologia Big Data dzieli się głównie na dwa typy:
- operacyjne technologie Big Data
- analityczne technologie Big Data

po pierwsze, operacyjne Big Data to normalne, codzienne dane, które generujemy. Mogą to być transakcje Online, Media społecznościowe lub dane z konkretnej organizacji itp. Można nawet uznać, że jest to rodzaj surowych danych, które są wykorzystywane do zasilania analitycznych technologii Big Data.
oto kilka przykładów operacyjnych technologii Big Data:
- rezerwacja biletów Online, która obejmuje bilety kolejowe, bilety lotnicze, bilety do kina itp.
- zakupy Online, czyli Amazon, Flipkart, Walmart, Snap deal i wiele innych.Facebook, Instagram, co to jest aplikacja i wiele więcej.
- dane pracownika dowolnej międzynarodowej firmy.
dzięki temu przejdźmy do analitycznych technologii Big Data.
analityczne Big Data jest jak zaawansowana wersja technologii Big Data. Jest to trochę skomplikowane niż operacyjne Big Data. Krótko mówiąc, analityczne big data to miejsce, w którym faktyczna część wydajności wchodzi w obraz, a kluczowe decyzje biznesowe w czasie rzeczywistym są podejmowane poprzez analizę operacyjnych Big Data.
Oto kilka przykładów analitycznych technologii Big Data:

- Stock marketing
- Przeprowadzanie misji kosmicznych, w których każdy kawałek informacji jest kluczowy.
- informacje o prognozie pogody.
- dziedziny medyczne, w których można monitorować stan zdrowia konkretnego pacjenta.
przyjrzyjmy się najlepszym technologiom Big Data stosowanym w branży IT.
najlepsze technologie Big Data
najlepsze technologie big data Są podzielone na 4 dziedziny, które są sklasyfikowane w następujący sposób:
- przechowywanie danych
- Eksploracja danych
- Analiza danych
- Wizualizacja danych
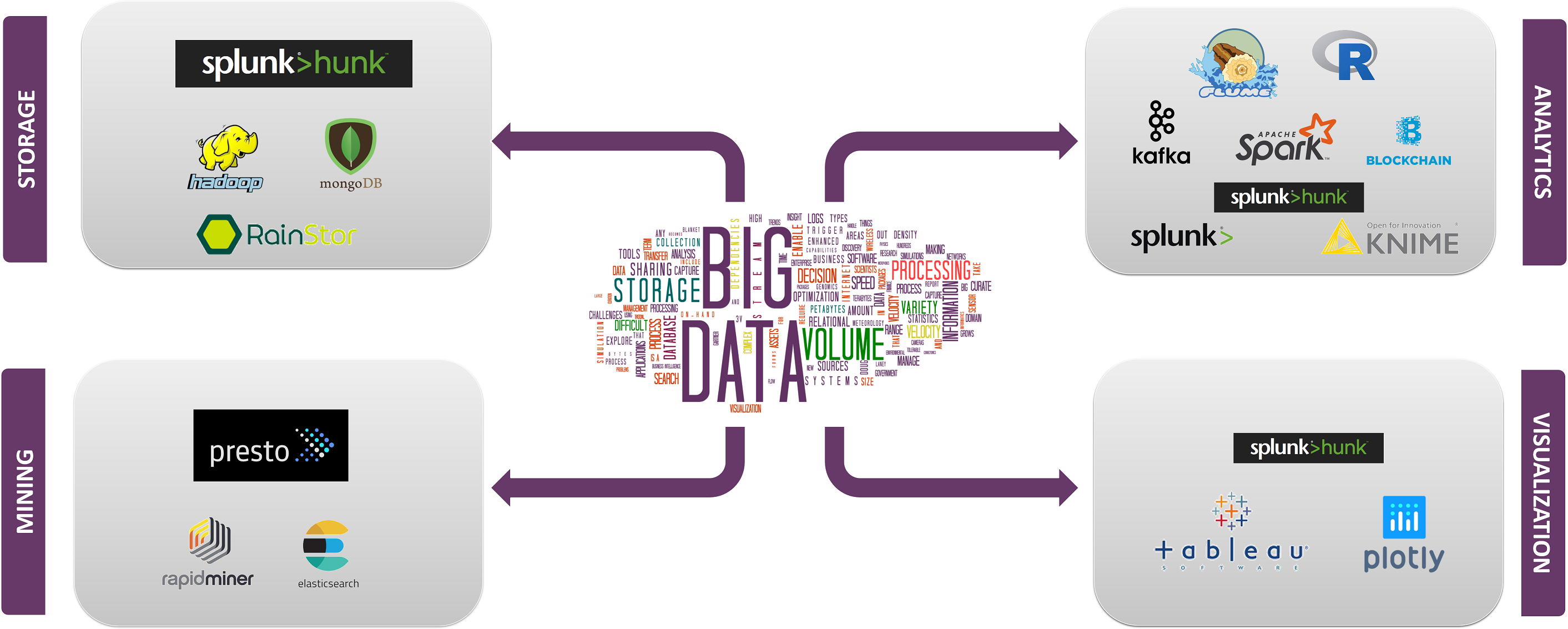
teraz zajmijmy się technologiami należącymi do każdej z tych kategorii wraz z ich faktami i możliwościami, wraz z firmami, które ich używają.
Zacznijmy od technologii Big Data w przechowywaniu danych.
przechowywanie danych
Hadoop
![]()
Hadoop Framework został zaprojektowany do przechowywania i przetwarzania danych w rozproszonym środowisku przetwarzania danych z towarowym sprzętem za pomocą prostego modelu programowania. Może przechowywać i analizować dane obecne w różnych maszynach przy dużych prędkościach i niskich kosztach.
-
-
-
-
- opracowany przez: Apache Software Foundation w roku 2011 10 grudnia.
- napisane w: JAVA
- aktualna stabilna wersja: Hadoop 3.11
-
-
-
firmy korzystające z Hadoop:
MongoDB

bazy danych dokumentów NoSQL, takie jak MongoDB, stanowią bezpośrednią alternatywę dla sztywnego schematu używanego w relacyjnych bazach danych. Dzięki temu MongoDB może oferować elastyczność przy obsłudze szerokiej gamy typów danych w dużych wolumenach i na różnych architekturach rozproszonych.
-
-
-
-
- opracowany przez: MongoDB w roku 2009 11 lutego
- napisane w: C++, GO, JavaScript, Python
- aktualna stabilna wersja: MongoDB 4.0.10
-
-
-
firmy korzystające z MongoDB:

Rainstor
![]() RainStor jest firmą programistyczną, która opracowała system zarządzania bazami danych o tej samej nazwie przeznaczony do zarządzania i analizy Big Data dla dużych przedsiębiorstw. Wykorzystuje techniki deduplikacji do organizowania procesu przechowywania dużych ilości danych w celach informacyjnych.
RainStor jest firmą programistyczną, która opracowała system zarządzania bazami danych o tej samej nazwie przeznaczony do zarządzania i analizy Big Data dla dużych przedsiębiorstw. Wykorzystuje techniki deduplikacji do organizowania procesu przechowywania dużych ilości danych w celach informacyjnych.
-
-
-
-
- opracowany przez: RainStor Software company w roku 2004.
- działa jak: SQL
- aktualna stabilna wersja: RainStor 5.5
-
-
-
firmy korzystające z RainStor:

Hunk

Hunk umożliwia dostęp do danych w zdalnych klastrach Hadoop za pośrednictwem wirtualnych indeksów i pozwala używać języka przetwarzania wyszukiwania Splunk do analizy danych. Dzięki Hunk możesz raportować i wizualizować duże ilości danych ze źródeł Hadoop i NoSQL.
-
-
-
-
- opracowany przez: Splunk INC w roku 2013.
- napisane w: JAVA
- aktualna wersja stabilna: Splunk Hunk 6.2
-
-
-
przejdźmy teraz do technologii Big Data wykorzystywanych w eksploracji danych.
Eksploracja danych
Presto

Presto to rozproszony Silnik zapytań SQL o otwartym kodzie źródłowym do uruchamiania interaktywnych zapytań analitycznych wobec źródeł danych o różnej wielkości, od gigabajtów do petabajtów. Presto umożliwia odpytywanie danych w Hive, Cassandra, relacyjnych bazach danych i własnościowych magazynach danych.
-
-
-
-
- opracowany przez: Apache Foundation w roku 2013.
- napisane w: JAVA
- aktualna stabilna wersja: Presto 0.22
-
-
-
firmy korzystające z Presto:

Rapid Miner
![]()
RapidMiner to scentralizowane rozwiązanie, które oferuje bardzo wydajny i solidny graficzny interfejs użytkownika, który umożliwia użytkownikom tworzenie, dostarczanie i utrzymywanie analiz predykcyjnych. Umożliwia tworzenie bardzo zaawansowanych przepływów pracy, obsługę skryptów w kilku językach.
-
-
-
-
- opracowany przez: RapidMiner w roku 2001
- napisane w: JAVA
- aktualna stabilna wersja: RapidMiner 9.2
-
-
-
firmy korzystające z RapidMiner:

Elasticsearch
![]()
Elasticsearch to wyszukiwarka oparta na bibliotece Lucene. Zapewnia rozproszoną, wielotekstową, Pełnotekstową wyszukiwarkę z interfejsem WWW HTTP i dokumentami JSON niezawierającymi schematów.
-
-
-
-
- opracowany przez: Elastic NV w roku 2012.
- napisane w: JAVA
- aktualna stabilna wersja: ElasticSearch 7.1
-
-
-
firmy korzystające z Elasticsearch:

dzięki temu możemy teraz przejść do technologii Big Data wykorzystywanych w analityce danych.
Analiza danych

Apache Kafka jest rozproszoną platformą streamingową. Platforma strumieniowa ma trzy kluczowe funkcje, które są następujące:
-
-
-
-
- Wydawca
- Abonent
- konsument
-
-
-
jest to podobne do kolejki wiadomości lub korporacyjnego systemu przesyłania wiadomości.
- opracowany przez: Apache Software Foundation w roku 2011
- napisany w: Scala, JAVA
- aktualna stabilna wersja: Apache Kafka 2.2.0
firmy korzystające z Kafki:

Splunk
 Splunk przechwytuje, indeksuje i koreluje dane w czasie rzeczywistym w repozytorium z możliwością przeszukiwania, z którego może generować wykresy, raporty, alerty, pulpity nawigacyjne i wizualizacje danych. Jest również używany do zarządzania aplikacjami, bezpieczeństwa i zgodności, a także analityki biznesowej i internetowej.
Splunk przechwytuje, indeksuje i koreluje dane w czasie rzeczywistym w repozytorium z możliwością przeszukiwania, z którego może generować wykresy, raporty, alerty, pulpity nawigacyjne i wizualizacje danych. Jest również używany do zarządzania aplikacjami, bezpieczeństwa i zgodności, a także analityki biznesowej i internetowej.
-
-
-
-
- opracowany przez: Splunk INC W roku 2014 6 maja
- napisane w: AJAX, C++, Python, XML
- aktualna stabilna wersja: Splunk 7.3
-
-
-
firmy korzystające z Splunk:

KNIME
 KNIME umożliwia użytkownikom wizualne tworzenie przepływów danych, selektywne wykonywanie niektórych lub wszystkich etapów analizy i sprawdzanie wyników, modeli i interaktywnych widoków. KNIME jest napisany w Javie i oparty na Eclipse i wykorzystuje swój mechanizm rozszerzenia do dodawania wtyczek zapewniających dodatkową funkcjonalność.
KNIME umożliwia użytkownikom wizualne tworzenie przepływów danych, selektywne wykonywanie niektórych lub wszystkich etapów analizy i sprawdzanie wyników, modeli i interaktywnych widoków. KNIME jest napisany w Javie i oparty na Eclipse i wykorzystuje swój mechanizm rozszerzenia do dodawania wtyczek zapewniających dodatkową funkcjonalność.
-
-
-
-
- opracowane przez: KNIME w roku 2008
- napisane w: JAVA
- aktualna stabilna wersja: KNIME 3.7.2
-
-
-
firmy korzystające z KNIME:
 Iskra
Iskra

Spark zapewnia możliwości przetwarzania w pamięci, aby zapewnić szybkość, uogólniony Model wykonania obsługujący szeroką gamę aplikacji oraz interfejsy API Java, Scala i Python ułatwiające tworzenie.
-
-
-
-
- opracowany przez: Apache Software Foundation
- napisany w: Java, Scala, Python, R
- aktualna stabilna wersja: Apache Spark 2.4.3
-
-
-
firmy korzystające ze Spark:

R-język

R jest językiem programowania i wolnym środowiskiem programistycznym do obliczeń statystycznych i Grafiki. Język R jest szeroko stosowany wśród statystyków i eksploratorów danych do tworzenia oprogramowania statystycznego i głównie w analizie danych.
-
-
-
-
- opracowany przez: R-Foundation w roku 2000 29 lutego
- napisany w: Fortran
- aktualna stabilna wersja: R-3.6.0
-
-
-
firmy używające języka R:

Blockchain
![]() BlockChain jest używany w podstawowych funkcjach, takich jak płatności, DEPOZYT i tytuł może również zmniejszyć oszustwa, zwiększyć prywatność finansową, przyspieszyć transakcje i umiędzynarodowić rynki.
BlockChain jest używany w podstawowych funkcjach, takich jak płatności, DEPOZYT i tytuł może również zmniejszyć oszustwa, zwiększyć prywatność finansową, przyspieszyć transakcje i umiędzynarodowić rynki.
BlockChain może być wykorzystany do osiągnięcia następujących celów w środowisku sieci biznesowej:
-
-
-
-
- wspólna Księga: Tutaj możemy dołączyć rozproszony system rekordów w sieci biznesowej.
- inteligentny kontrakt: Warunki biznesowe są osadzone w bazie danych transakcji i realizowane za pomocą transakcji.
- Prywatność: zapewnienie odpowiedniej widoczności, transakcje są bezpieczne, uwierzytelnione i weryfikowalne
- konsensus: wszystkie strony w sieci biznesowej zgadzają się na zweryfikowane transakcje sieciowe.
-
-
-
- opracowany przez: Bitcoin
- napisany w: JavaScript, C++, Python
- aktualna stabilna wersja: Blockchain 4.0
firmy korzystające z Blockchain:

dzięki temu przejdziemy do wizualizacji danych Big Data technologies
Wizualizacja danych
Tableau

Tableau to potężne i najszybciej rozwijające się narzędzie do wizualizacji danych wykorzystywane w branży Business Intelligence. Analiza danych jest bardzo szybka dzięki Tableau, a tworzone wizualizacje mają postać pulpitów nawigacyjnych i arkuszy roboczych.
-
-
-
-
- opracowane przez: TableAU 2013 17 maja
- napisane w: JAVA, C++, Python, C
- aktualna stabilna wersja: TableAU 8.2
-
-
-
firmy korzystające z Tableau:

Plotly
![]()
głównie do tworzenia wykresów szybciej i bardziej wydajne. Biblioteki API dla Pythona, R, MATLAB, Node.js, Julia, Arduino i REST API. Plotly może być również używany do stylizacji interaktywnych wykresów za pomocą Jupyter notebook.
-
-
-
-
- opracowany przez: Plotly in the year 2012
- napisane w: JavaScript
- aktualna stabilna wersja: Plotly 1.47.4
-
-
-
firmy korzystające z Plotly:
 teraz omówmy pojawiające się technologie Big Data
teraz omówmy pojawiające się technologie Big Data
pojawiające się technologie Big Data
TensorFlow

TensorFlow posiada wszechstronny, Elastyczny ekosystem narzędzi, bibliotek i zasobów społecznościowych, który pozwala badaczom wprowadzać najnowocześniejsze technologie w uczeniu maszynowym, a deweloperzy mogą łatwo tworzyć i wdrażać aplikacje oparte na uczeniu maszynowym.
-
-
-
-
- opracowany przez: Google Brain Team w roku 2019
- napisane w: Python, C++, CUDA
- aktualna stabilna wersja: TensorFlow 2.0 beta
-
-
-
firmy korzystające z TensorFlow:

Beam
![]()
Apache Beam zapewnia przenośną warstwę API do tworzenia zaawansowanych równoległych potoków przetwarzania danych, które mogą być wykonywane w różnych silnikach wykonawczych lub prowadnicach.
-
-
-
-
- opracowany przez: Apache Software Foundation w roku 2016 15 czerwca
- napisane w: JAVA, Python
- aktualna stabilna wersja: Apache Beam 0.1.0.
-
-
-
firmy korzystające z Beam:
 Docker
Docker

Docker to narzędzie ułatwiające tworzenie, wdrażanie i uruchamianie aplikacji za pomocą kontenerów. Kontenery umożliwiają programistom spakowanie aplikacji ze wszystkimi potrzebnymi jej częściami, takimi jak biblioteki i inne zależności, i wysłanie ich wszystkich jako jednego pakietu.
-
-
-
-
- opracowany przez: Docker INC w roku 2003 13 marca.
- napisane w: Go
- aktualna stabilna wersja: Docker 18.09
-
-
-
firmy korzystające z Docker:

Airflow
![]() Apache Airflow to system automatyzacji i planowania przepływu pracy, który może być używany do tworzenia potoków danych i zarządzania nimi. Airflow wykorzystuje przepływy pracy wykonane z ukierunkowanych Wykresów acyklicznych (dag) zadań. Definiowanie przepływów pracy w kodzie zapewnia łatwiejszą konserwację, Testowanie i wersjonowanie.
Apache Airflow to system automatyzacji i planowania przepływu pracy, który może być używany do tworzenia potoków danych i zarządzania nimi. Airflow wykorzystuje przepływy pracy wykonane z ukierunkowanych Wykresów acyklicznych (dag) zadań. Definiowanie przepływów pracy w kodzie zapewnia łatwiejszą konserwację, Testowanie i wersjonowanie.
-
-
-
-
- opracowany przez: Apache Software Foundation 15 maja 2019 r.
- napisany w: Python
- aktualna stabilna wersja: Apache AirFlow 1.10.3
-
-
-
firmy korzystające z przepływu powietrza:

Kubernetes
 Kubernetes to niezależne od dostawcy narzędzie do zarządzania klastrami i kontenerami, otwarte od Google w 2014 roku. Zapewnia platformę do automatyzacji, wdrażania, skalowania i obsługi kontenerów aplikacji w klastrach hostów.
Kubernetes to niezależne od dostawcy narzędzie do zarządzania klastrami i kontenerami, otwarte od Google w 2014 roku. Zapewnia platformę do automatyzacji, wdrażania, skalowania i obsługi kontenerów aplikacji w klastrach hostów.
-
-
-
-
- opracowany przez: Cloud Native Computing Foundation w roku 2015 21 lipca
- napisane w: Go
- aktualna stabilna wersja: Kubernetes 1.14
-
-
-
firmy korzystające z Kubernetes:

z tym dochodzimy do końca tego artykułu. Mam nadzieję, że rzuciłem trochę światła na Twoją wiedzę na temat Big Data i jego technologii.
teraz, gdy zrozumiałeś Big data i jego technologie, sprawdź Szkolenie Hadoop prowadzone przez Edureka, zaufaną firmę edukacyjną online z siecią ponad 250 000 zadowolonych uczniów na całym świecie. Szkolenie certyfikacyjne Edureka Big Data Hadoop pomaga uczniom stać się ekspertem w dziedzinie HDFS, Yarn, MapReduce, Pig, Hive, HBase, Oozie, Flume i Sqoop przy użyciu przypadków użycia w czasie rzeczywistym w handlu detalicznym, mediach społecznościowych, lotnictwie, turystyce i finansach.