Top Big Data Technologies that you Need to know
Big Data Technologies, The Buzz-word which you get to hear much in the recent days. Neste artigo, vamos discutir as tecnologias inovadoras que fizeram grandes dados espalhar seus ramos para alcançar maiores alturas.
- o que é a grande tecnologia de dados?
- tipos de grandes tecnologias de dados
- Top Big Data Technologies
- Emerging Big Data Technologies
What is Big Data Technology?
a grande tecnologia de dados pode ser definida como um utilitário de Software que é projetado para analisar, processar e extrair a informação de um conjunto de dados extremamente complexo e grande que o Software de processamento de dados tradicional nunca poderia lidar.

precisamos de Grandes Tecnologias de Processamento de Dados para Analisar esta enorme quantidade de dados em tempo Real e chegar a Conclusões e Previsões para reduzir os riscos no futuro.Agora vamos dar uma olhada nas categorias nas quais as grandes tecnologias de dados são classificadas:
Tipos de Dados Grandes Tecnologias:
Grande Tecnologia de Dados é principalmente classificado em dois tipos::
- Operacional de Big Data Tecnologias
- Analíticos de Big Data Tecnologias

em Primeiro lugar, O Operacional, o Big Data é tudo sobre o normal do dia-a-dia de dados que geramos. Podem ser as transações Online, as mídias sociais, ou os dados de uma determinada organização, etc. Você pode até considerar isso como uma espécie de dados brutos que é usado para alimentar as tecnologias analíticas de grandes dados.
alguns exemplos de grandes tecnologias de Dados Operacionais são os seguintes::
- reservas de bilhetes Online, que inclui os seus bilhetes de comboio, bilhetes de voo, bilhetes de cinema, etc.
- compras Online que é a sua Amazon, Flipkart, Walmart, Snap deal e muito mais.Facebook, Instagram, o que é app e muito mais.
- os dados relativos aos empregados de qualquer empresa multinacional.Então, com isso vamos passar para as tecnologias analíticas de grandes dados.Os grandes dados analíticos são como a versão avançada das grandes tecnologias de dados. É um pouco complexo do que os grandes dados operacionais. Em resumo, grandes dados analíticos é onde a parte de desempenho real entra na imagem e as decisões cruciais de negócios em tempo real são feitas através da análise dos grandes dados operacionais.
Alguns exemplos de Analítica de Big Data Tecnologias são como segue:

- Ações de marketing
- realizar as missões espaciais, onde cada bit de informação é crucial.
- informações relativas às previsões meteorológicas.Campos médicos onde um determinado estado de saúde pode ser monitorizado.
vamos dar uma olhada nas grandes tecnologias de dados que estão sendo usadas nas indústrias de TI.
Top Big Data Technologies
Top big data technologies are divided into 4 fields which are classified as follows:
- Data Storage
- Data Mining
- Data Analytics
- Data Visualization
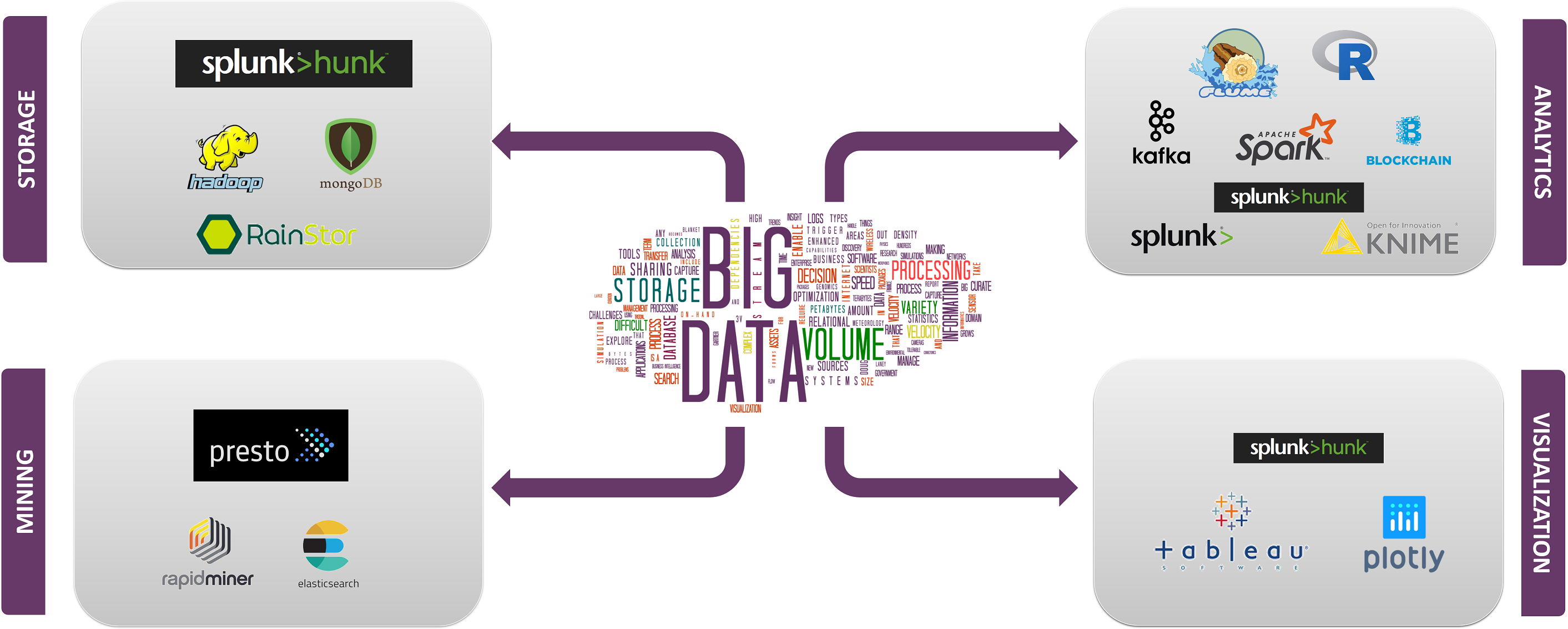
tratemos agora das tecnologias abrangidas por cada uma destas categorias com os seus factos e capacidades, juntamente com as empresas que as utilizam.Vamos começar com grandes tecnologias de dados no armazenamento de dados.
Data Storage
Hadoop

o Framework Hadoop foi projetado para armazenar e processar dados em um ambiente de processamento de dados distribuído com hardware commodity com um modelo de programação simples. Pode armazenar e analisar os dados presentes em diferentes máquinas com altas velocidades e baixos custos.
-
-
-
-
- Desenvolvido por: Apache Software Foundation, no ano de 2011, de 10 de Dezembro.
- escrito em: JAVA
- versão estável atual: Hadoop 3.11
-
-
-
as Empresas que usam Hadoop:

MongoDB

O NoSQL Documento como Bancos de dados MongoDB, oferecemos uma alternativa direto para o esquema rígido usado em Bancos de dados Relacionais. Isso permite que o MongoDB ofereça flexibilidade enquanto lida com uma grande variedade de tipos de dados em grandes volumes e em arquiteturas distribuídas.
-
-
-
-
- Desenvolvido por: MongoDB no ano de 2009, de 11 de Fevereiro
- Escrito em: C++, Vá, JavaScript, Python
- versão estável Atual: MongoDB 4.0.10
-
-
-
Empresas Usando o MongoDB:

Rainstor
 RainStor é uma empresa de software que desenvolveu um Sistema de Gerenciamento de Banco de mesmo nome, desenvolvido para Gerenciar e Analisar Big Data para empresas de grande porte. Ele usa técnicas de de deduplicação para organizar o processo de armazenamento de grandes quantidades de dados para referência.
RainStor é uma empresa de software que desenvolveu um Sistema de Gerenciamento de Banco de mesmo nome, desenvolvido para Gerenciar e Analisar Big Data para empresas de grande porte. Ele usa técnicas de de deduplicação para organizar o processo de armazenamento de grandes quantidades de dados para referência.-
-
-
-
- Desenvolvido por: RainStor empresa de Software no ano de 2004.
- Funciona como: SQL
- versão estável Atual: RainStor 5.5
-
-
-
as Empresas que utilizam RainStor:

Hunk

Pedaço permite-lhe aceder a dados remotos Clusters Hadoop através de índices virtuais e permite que você use o Splunk de Pesquisa de Processamento de Linguagem para analisar seus dados. Com o Hunk, você pode relatar e visualizar grandes quantidades de suas fontes de dados Hadoop e NoSQL.
-
-
-
-
- Desenvolvido por: Splunk INC no ano de 2013.
- Escrito em: JAVA
- versão estável Atual: Splunk Pedaço 6.2
-
-
-
Agora, vamos nos mover em Big Data Tecnologias utilizadas na Mineração de Dados.
extracção de dados
Presto

Presto é um motor de consulta SQL distribuído de código aberto para executar consultas analíticas interativas contra fontes de dados de todos os tamanhos que variam de Gigabytes a Petabytes. Presto permite pesquisar dados em Colmeia, Cassandra, bases de Dados Relacionais e armazenamento de dados proprietário.
-
-
-
-
- Desenvolvido por: Apache Foundation no ano de 2013.
- escrito em: JAVA
- versão estável atual: Presto 0.22
-
-
-
Empresas Utilizando o Presto:

Rapid Miner

RapidMiner é uma solução Centralizada que apresenta uma muito poderosa e robusta Interface Gráfica do Usuário que permite aos usuários Criar, Entregar e manter a análise Preditiva. Ele permite criar fluxos de trabalho muito avançados, Suporte de scripts em várias línguas.
-
-
-
-
- Desenvolvido por: RapidMiner no ano de 2001
- Escrito em: JAVA
- versão estável Atual: RapidMiner 9.2
-
-
-
as Empresas que utilizam o RapidMiner:

Elasticsearch

Elasticsearch é um Motor de Busca baseado na Biblioteca Lucene. Ele fornece um motor de busca de texto completo e distribuído, com uma Interface web HTTP e documentos JSON livres de esquemas.
-
-
-
-
- Desenvolvido por: Elastic NV no ano de 2012.
- Escrito em: JAVA
- versão estável Atual: ElasticSearch 7.1
-
-
-
as Empresas que utilizam o Elasticsearch:

Com isso, podemos agora mover-se em Big Data Tecnologias utilizadas na análise de Dados.
dados analíticos
Kafka

Apache Kafka é uma plataforma de Streaming distribuída. Uma plataforma de streaming tem três capacidades-chave que são as seguintes::
-
-
-
-
- o Publisher
- Assinante
- Consumidor
-
-
-
Isso é semelhante a uma Fila de Mensagem ou de um Sistema de Mensagens Corporativo.
- Desenvolvido por: Apache Software Foundation, no ano de 2011
- Escrito em: Scala, JAVA
- versão estável Atual: Apache Kafka 2.2.0
as Empresas que utilizam Kafka:

Splunk
 Splunk captures, Indexes, and correlates Real-time data in a Searchable Repository from which it can generate Graphs, Reports, alertas, Dashboards, and Data Visualizations. Ele também é usado para gestão de aplicativos, Segurança e conformidade, bem como análise de negócios e Web.
Splunk captures, Indexes, and correlates Real-time data in a Searchable Repository from which it can generate Graphs, Reports, alertas, Dashboards, and Data Visualizations. Ele também é usado para gestão de aplicativos, Segurança e conformidade, bem como análise de negócios e Web.-
-
-
-
- Desenvolvido por: Splunk INC no ano de 2014, a 6 de Maio
- Escrito em: AJAX, C++, Python, XML
- versão estável Atual: Splunk 7.3
-
-
-
as Empresas que utilizam o Splunk:

KNIME
 KNIME permite aos usuários criar visualmente Fluxos de Dados, Seletivamente executar algumas ou Todas as etapas de Análise, e Inspecionar os Resultados, os Modelos e as visualizações Interativas. KNIME é escrito em Java e baseado no Eclipse e faz uso de seu mecanismo de extensão para adicionar Plugins fornecendo funcionalidade adicional.
KNIME permite aos usuários criar visualmente Fluxos de Dados, Seletivamente executar algumas ou Todas as etapas de Análise, e Inspecionar os Resultados, os Modelos e as visualizações Interativas. KNIME é escrito em Java e baseado no Eclipse e faz uso de seu mecanismo de extensão para adicionar Plugins fornecendo funcionalidade adicional.-
-
-
-
- Desenvolvido por: KNIME no ano de 2008
- Escrito em: JAVA
- versão estável Atual: KNIME 3.7.2
-
-
-
as Empresas que utilizam o KNIME:
 Faísca
Faísca
de Ignição fornece Na Memória, as capacidades de Computação para oferecer Velocidade, uma Generalizada do Modelo de Execução para oferecer suporte a uma ampla variedade de aplicações, e Java, Scala, e Python APIs para facilitar o desenvolvimento.
-
-
-
-
- Desenvolvido por: Apache Software Foundation
- Escrito em: Java, Scala, Python, R
- versão estável Atual: Apache Faísca 2.4.3
-
-
-
Empresas Usando o Spark:

R-Língua

R é uma Linguagem de Programação e ambiente de software livre para Computação Estatística e Gráficos. A linguagem R é amplamente utilizada entre os estatísticos e mineiros de dados para o desenvolvimento de Software estatístico e, principalmente, na análise de dados.
-
-
-
-
- Desenvolvido por: R-Fundação no ano de 2000, de 29 de Fevereiro
- Escrito em: Fortran
- versão estável Atual: R-3.6.0
-
-
-
as Empresas que utilizam o R-Língua:

Blockchain
 BlockChain é utilizado em funções essenciais, tais como o pagamento de caução, e o título também pode reduzir a fraude, aumentar a privacidade financeira, agilizar as transações, e internacionalização dos mercados.
BlockChain é utilizado em funções essenciais, tais como o pagamento de caução, e o título também pode reduzir a fraude, aumentar a privacidade financeira, agilizar as transações, e internacionalização dos mercados.BlockChain pode ser utilizado para alcançar o seguinte em um Ambiente de Rede de Negócios:
-
-
-
-
- Compartilhado de Contabilidade: Aqui podemos adicionar o sistema distribuído de registros através de uma rede de negócios.Contrato inteligente: os Termos de negócio são incorporados na Base de dados de transações e executados com transações.Privacidade: garantir a visibilidade apropriada, as transacções são seguras, autenticadas e verificáveis.consenso: todas as partes numa rede de negócios concordam com as transacções verificadas na rede.
-
-
-
- Desenvolvido por: Bitcoin
- Escrito em: JavaScript, C++, Python
- versão estável Atual: Blockchain 4.0
as Empresas que utilizam Blockchain:

Com isso, passar-se-ão em Visualização de Dados de Dados Big tecnologias
Visualização de Dados
Tableau

o Tableau é um Poderoso e de mais Rápido crescimento ferramenta de Visualização de Dados usado em Inteligência de Negócios da Indústria. A análise de dados é muito rápida com Tableau e as visualizações criadas são na forma de painéis e planilhas.
-
-
-
-
- Desenvolvido por: TableAU De 2013 a 17 de Maio
- Escrito em: JAVA, C++, Python, C
- versão Actual e estável: o TableAU 8.2
-
-
-
as Empresas que utilizam o Tableau:

Plotly

usado Principalmente para fazer a criação de Gráficos mais rápido e mais eficiente. Bibliotecas API para Python, R, MATLAB, Node.js, Julia e Arduino e uma API de descanso. Plotly can also be used to style Interactive Graphs with Jupyter notebook.
-
-
-
-
- Desenvolvido por: Plotly no ano de 2012
- Escrito em: JavaScript
- versão estável Atual: Plotly 1.47.4
-
-
-
as Empresas que utilizam Plotly:Agora vamos discutir as tecnologias emergentes de grandes dados.

TensorFlow tem um ecossistema abrangente e flexível de ferramentas, bibliotecas e recursos comunitários que permite aos pesquisadores empurrar o estado da arte na aprendizagem de máquinas e desenvolvedores podem facilmente construir e implantar aplicações movidas a máquina de aprendizagem.
-
-
-
-
- Desenvolvido por: Google Cérebro da Equipe no ano de 2019
- Escrito em: Python, C++, CUDA
- versão estável Atual: TensorFlow 2.0 beta
-
-
-
as Empresas que utilizam TensorFlow:

Feixe

Apache Feixe fornece um Portátil camada de API para a construção de sofisticados Paralela de Processamento de Dados Condutas que podem ser executadas através de uma diversidade de Motores de Execução ou Corredores.
-
-
-
-
- Desenvolvido por: Apache Software Foundation in the year 2016 June 15
- Written in: JAVA, Python
- Current stable version: Apache Beam 0.1.0 incubating.
-
-
-
as Empresas que utilizam Feixe de:
 janela de Encaixe
janela de Encaixe
Docker é uma ferramenta projetada para tornar mais fácil para Criar, Implementar e Executar aplicações usando Recipientes. Containers allow a developer to Package up an application with all of the parts it needs, such as Libraries and other Dependencies, and Ship it all out as One Package.
-
-
-
-
- desenvolvido por: Docker INC no ano 2003 13 de Março.
- escrito em: Go
- versão estável actual: Docker 18.09
-
-
-
empresas que utilizam a Docker:

Airflow é um sistema de automação de fluxo de trabalho e agendamento que pode ser usado para criar e gerenciar dutos de dados. Airflow usa fluxos de trabalho feitos de Grafos acíclicos direcionados (DAGs) de Tarefas. Definir fluxos de trabalho em código fornece manutenção mais fácil, testes e versionamento.
-
-
-
-
- Desenvolvido por: Apache Software Foundation em 15 de Maio de 2019
- Escrito em: Python
- versão estável Atual: Apache Fluxo de ar 1.10.3
-
-
-
As empresas que utilizam o Fluxo de ar:

Kubernetes
 Kubernetes é um Fornecedor independente de Cluster e o Recipiente de ferramenta de Gestão de código-fonte Aberto pelo Google em 2014. Ele fornece uma plataforma para automação, implantação, escala e operações de contêineres de aplicação em Clusters de Hosts.
Kubernetes é um Fornecedor independente de Cluster e o Recipiente de ferramenta de Gestão de código-fonte Aberto pelo Google em 2014. Ele fornece uma plataforma para automação, implantação, escala e operações de contêineres de aplicação em Clusters de Hosts.-
-
-
-
- Desenvolvido por: Nuvem Nativo de Computação Fundação, no ano de 2015, de 21 de julho de
- Escrito em: Go
- versão estável Atual: Kubernetes 1.14
-
-
-
as Empresas que utilizam Kubernetes:

Com isso, chegamos ao fim deste artigo. Espero ter lançado alguma luz sobre o seu conhecimento sobre grandes dados e suas Tecnologias.
agora que você entendeu grandes dados e suas Tecnologias, confira o treinamento Hadoop por Edureka, uma empresa de Aprendizagem Online confiável com uma rede de mais de 250.000 alunos satisfeitos espalhados por todo o mundo. O curso de formação da Edureka Big Data Hadoop Certification Training course ajuda os alunos a tornarem-se especialistas em HDFS, Yarn, MapReduce, Pig, Hive, HBase, Oozie, Flume e Sqoop utilizando casos de utilização em tempo real no domínio retalhista, das redes sociais, da aviação, do Turismo e das Finanças.