Cele mai mari tehnologii de date pe care trebuie să le cunoașteți
tehnologii de date mari, cuvântul Buzz pe care îl auziți mult în ultimele zile. În acest articol, vom discuta despre tehnologiile inovatoare care au făcut ca Big Data să-și răspândească ramurile pentru a atinge înălțimi mai mari.
- ce este tehnologia Big Data?
- tipuri de tehnologii Big Data
- Top tehnologii Big Data
- tehnologii emergente Big Data
ce este tehnologia Big Data?
tehnologia Big Data poate fi definită ca un utilitar Software care este conceput pentru a analiza, procesa și extrage informațiile dintr-un set de date extrem de complex și de mari, cu care Software-ul tradițional de procesare a datelor nu ar putea face față niciodată.

avem nevoie de tehnologii mari de procesare a datelor pentru a analiza această cantitate imensă de date în timp real și pentru a veni cu concluzii și previziuni pentru a reduce riscurile în viitor.
acum să aruncăm o privire la categoriile în care sunt clasificate tehnologiile Big Data:
tipuri de tehnologii Big Data:
tehnologia Big Data este clasificată în principal în două tipuri:
- tehnologii operaționale Big Data
- tehnologii analitice Big Data

în primul rând, datele operaționale mari se referă la datele normale de zi cu zi pe care le generăm. Acestea ar putea fi tranzacțiile Online, rețelele sociale sau datele de la o anumită organizație etc. Puteți chiar să considerați acest lucru ca fiind un fel de date brute care sunt utilizate pentru a alimenta tehnologiile analitice de date mari.
câteva exemple de tehnologii operaționale de date mari sunt următoarele:
- rezervările de bilete Online, care include biletele de tren, bilete de avion, bilete de film etc.
- cumpărături Online, care este Amazon, Flipkart, Walmart, ajustare afacere și multe altele.
- date de pe site-urile de socializare precum Facebook, Instagram, Ce este aplicația și multe altele.
- detaliile angajaților oricărei companii multinaționale.
deci, cu aceasta să ne mutăm în tehnologiile analitice de date mari.
Big Data analitică este ca versiunea avansată a tehnologiilor Big Data. Este un pic complex decât datele operaționale mari. Pe scurt, Big data analitică este locul în care partea de performanță reală intră în imagine și deciziile cruciale de afaceri în timp real sunt luate prin analizarea datelor mari operaționale.
câteva exemple de tehnologii analitice de date mari sunt după cum urmează:

- Stock marketing
- efectuarea misiunilor spațiale în care fiecare bit de informații este crucial.
- informații despre prognoza meteo.
- domenii medicale în care poate fi monitorizată starea de sănătate a unui anumit pacient.
să aruncăm o privire la tehnologiile de top Big Data utilizate în industriile IT.
Top Big Data Technologies
top Big data technologies sunt împărțite în 4 câmpuri care sunt clasificate după cum urmează:
- stocarea datelor
- exploatarea datelor
- analiza datelor
- vizualizarea datelor
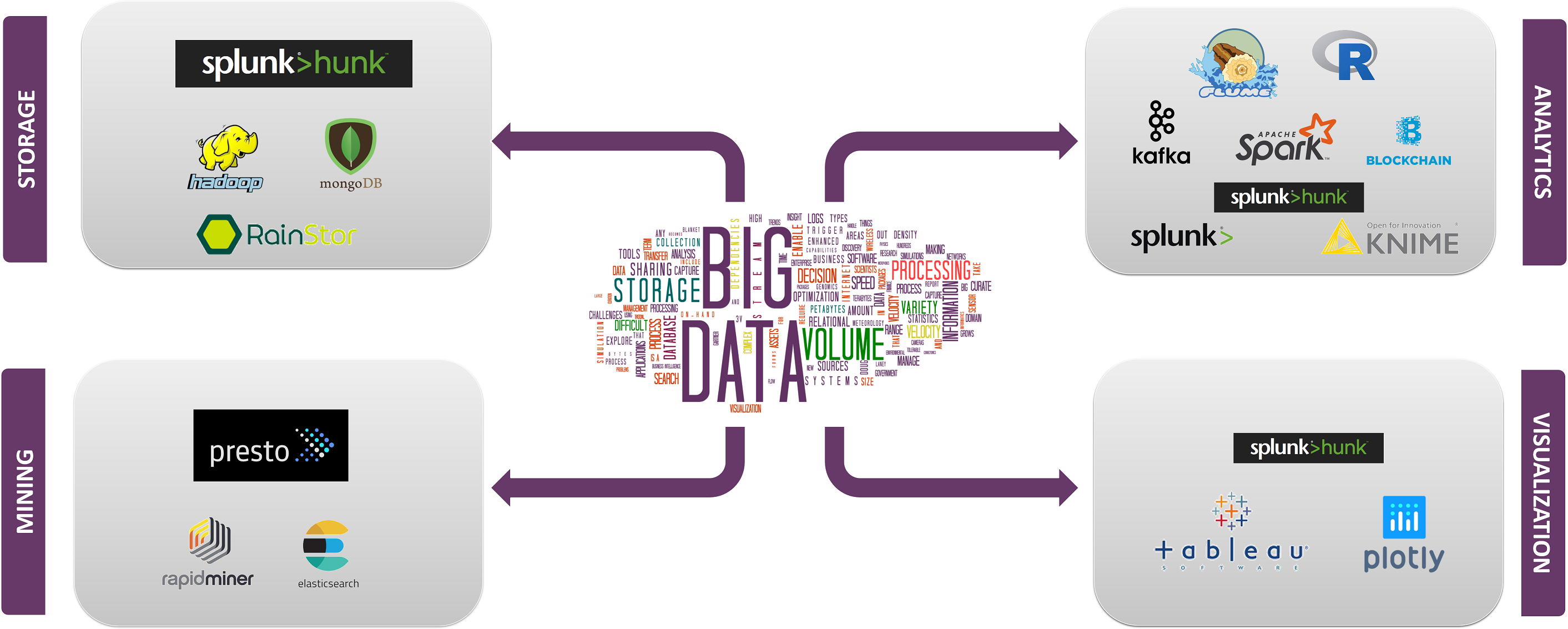
acum să ne ocupăm de tehnologiile care se încadrează în fiecare dintre aceste categorii cu faptele și capacitățile lor, împreună cu companiile care le folosesc.
să începem cu tehnologiile Big Data în stocarea datelor.
Stocare date
Hadoop
![]()
Hadoop Framework a fost conceput pentru a stoca și prelucra date într-un mediu distribuit de procesare a datelor cu hardware de mărfuri cu un model simplu de programare. Poate stoca și analiza datele prezente în diferite mașini cu viteze mari și Costuri reduse.
-
-
-
-
- dezvoltat de: Apache Software Foundation în anul 2011 10 decembrie.
- scris în: JAVA
- versiune stabilă curentă: Hadoop 3.11
-
-
-
companiile care utilizează Hadoop:
MongoDB

bazele de date de documente NoSQL precum MongoDB, oferă o alternativă directă la schema rigidă utilizată în bazele de date relaționale. Acest lucru permite MongoDB să ofere flexibilitate în timp ce gestionează o mare varietate de tipuri de date la volume mari și pe arhitecturi distribuite.
-
-
-
-
- dezvoltat de: MongoDB în anul 2009 11 februarie
- scris în: C++, Go, JavaScript, Python
- versiunea actuală stabilă: MongoDB 4.0.10
-
-
-
companii care utilizează MongoDB:

Rainstor
![]() RainStor este o companie de software care a dezvoltat un sistem de gestionare a bazelor de date cu același nume conceput pentru a gestiona și analiza Big Data pentru întreprinderile mari. Utilizează tehnici de deduplicare pentru a organiza procesul de stocare a unor cantități mari de date pentru referință.
RainStor este o companie de software care a dezvoltat un sistem de gestionare a bazelor de date cu același nume conceput pentru a gestiona și analiza Big Data pentru întreprinderile mari. Utilizează tehnici de deduplicare pentru a organiza procesul de stocare a unor cantități mari de date pentru referință.
-
-
-
-
- dezvoltat de: RainStor Software company în anul 2004.
- funcționează ca: SQL
- versiune stabilă curentă: RainStor 5.5
-
-
-
companii care utilizează RainStor:

Clit

Hunk vă permite să accesați datele din clusterele Hadoop de la distanță prin indici virtuali și vă permite să utilizați limbajul de procesare a căutării Splunk pentru a vă analiza datele. Cu Hunk, puteți raporta și vizualiza cantități mari din sursele de date Hadoop și NoSQL.
-
-
-
-
- dezvoltat de: Splunk INC în anul 2013.
- scris în: JAVA
- versiunea actuală stabilă: Splunk Hunk 6.2
-
-
-
acum, să trecem la tehnologiile Big Data utilizate în extragerea datelor.
Data Mining
Presto

Presto este un motor de interogare SQL distribuit open source pentru rularea interogărilor analitice Interactive împotriva surselor de date de toate dimensiunile, de la Gigabytes la Petabytes. Presto permite interogarea datelor în Hive, Cassandra, baze de date relaționale și magazine de date proprietare.
-
-
-
-
- dezvoltat de: Fundația Apache în anul 2013.
- scris în: JAVA
- versiune stabilă curentă: Presto 0.22
-
-
-
companii care utilizează Presto:

Rapid Miner
![]()
RapidMiner este o soluție centralizată care oferă o interfață grafică de utilizator foarte puternică și robustă, care permite utilizatorilor să creeze, să livreze și să mențină analize Predictive. Permite crearea de fluxuri de lucru foarte avansate, Suport pentru scripturi în mai multe limbi.
-
-
-
-
- dezvoltat de: RapidMiner în anul 2001
- scris în: JAVA
- versiunea actuală stabilă: RapidMiner 9.2
-
-
-
companii care utilizează RapidMiner:

Elasticsearch
![]()
Elasticsearch este un motor de căutare bazat pe Biblioteca Lucene. Acesta oferă un motor de căutare full-Text distribuit, capabil de mai multe entități, cu o interfață web HTTP și documente JSON fără schemă.
-
-
-
-
- dezvoltat de: Elastic NV în anul 2012.
- scris în: JAVA
- versiune stabilă curentă: ElasticSearch 7.1
-
-
-
companii care utilizează Elasticsearch:

cu aceasta, acum putem trece la tehnologiile Big Data utilizate în analiza datelor.
analiza datelor
Kafka

Apache Kafka este o platformă de Streaming distribuită. O platformă de streaming are trei capabilități cheie care sunt următoarele:
-
-
-
-
- Editor
- abonat
- consumator
-
-
-
acest lucru este similar cu o coadă de mesaje sau un sistem de mesagerie întreprindere.
- dezvoltat de: Apache Software Foundation în anul 2011
- scris în: Scala, JAVA
- versiunea actuală stabilă: Apache Kafka 2.2.0
companii care utilizează Kafka:

Splunk
 Splunk captează, indexează și corelează datele în timp real într-un depozit de căutare din care poate genera grafice, rapoarte, alerte, tablouri de bord și vizualizări de date. De asemenea, este utilizat pentru gestionarea aplicațiilor, securitate și conformitate, precum și pentru analize de afaceri și Web.
Splunk captează, indexează și corelează datele în timp real într-un depozit de căutare din care poate genera grafice, rapoarte, alerte, tablouri de bord și vizualizări de date. De asemenea, este utilizat pentru gestionarea aplicațiilor, securitate și conformitate, precum și pentru analize de afaceri și Web.
-
-
-
-
- dezvoltat de: Splunk INC în anul 2014 6 mai
- scris în: AJAX, C++, Python, XML
- versiunea actuală stabilă: Splunk 7.3
-
-
-
companiile care utilizează Splunk:

KNIME
 KNIME permite utilizatorilor să creeze vizual fluxuri de date, să execute selectiv unele sau toate etapele de analiză și să inspecteze rezultatele, modelele și vizualizările Interactive. KNIME este scris în Java și se bazează pe Eclipse și folosește mecanismul său de extensie pentru a adăuga pluginuri care oferă funcționalități suplimentare.
KNIME permite utilizatorilor să creeze vizual fluxuri de date, să execute selectiv unele sau toate etapele de analiză și să inspecteze rezultatele, modelele și vizualizările Interactive. KNIME este scris în Java și se bazează pe Eclipse și folosește mecanismul său de extensie pentru a adăuga pluginuri care oferă funcționalități suplimentare.
-
-
-
-
- dezvoltat de: KNIME în anul 2008
- scris în: JAVA
- versiunea actuală stabilă: KNIME 3.7.2
-
-
-
companii care folosesc KNIME:
 Spark
Spark

Spark oferă capabilități de calcul în memorie pentru a oferi viteză, un Model de execuție generalizat pentru a sprijini o mare varietate de aplicații și API-uri Java, Scala și Python pentru ușurința dezvoltării.
-
-
-
-
- dezvoltat de: Apache Software Foundation
- scris în: Java, Scala, Python, R
- versiunea actuală stabilă: Apache Spark 2.4.3
-
-
-
companii care utilizează Spark:

R-limba

R este un limbaj de programare și un mediu software liber pentru calcul statistic și grafică. Limbajul R este utilizat pe scară largă în rândul Statisticienilor și minerilor de date pentru dezvoltarea de Software statistic și în principal în analiza datelor.
-
-
-
-
- dezvoltat de: R-Fundația în anul 2000 29 februarie
- scris în: Fortran
- curent versiune stabilă: R-3.6.0
-
-
-
companii care utilizează R-Language:

Blockchain
![]() BlockChain este utilizat în funcții esențiale, cum ar fi plata, escrow și titlul, de asemenea, poate reduce frauda, crește confidențialitatea financiară, accelerează tranzacțiile și internaționalizează piețele.
BlockChain este utilizat în funcții esențiale, cum ar fi plata, escrow și titlul, de asemenea, poate reduce frauda, crește confidențialitatea financiară, accelerează tranzacțiile și internaționalizează piețele.
BlockChain poate fi utilizat pentru realizarea următoarelor într-un mediu de rețea de afaceri:
-
-
-
-
- registrul comun: Aici putem adăuga sistemul distribuit de înregistrări într-o rețea de afaceri.
- contract inteligent: Termenii de afaceri sunt încorporați în baza de date a tranzacțiilor și executați cu tranzacții.
- Confidențialitate: asigurarea unei vizibilități adecvate, tranzacțiile sunt sigure, autentificate și verificabile
- consens: toate părțile dintr-o rețea de afaceri sunt de acord cu tranzacțiile verificate în rețea.
-
-
-
- dezvoltat de: Bitcoin
- scris în: JavaScript, C++, Python
- versiunea actuală stabilă: Blockchain 4.0
companiile care folosesc Blockchain:

cu aceasta, ne vom muta în vizualizarea datelor Big Data technologies
vizualizarea datelor
Tableau

Tableau este un instrument puternic și cea mai rapidă creștere de vizualizare a datelor utilizate în industria de Business Intelligence. Analiza datelor este foarte rapidă cu Tableau, iar vizualizările create sunt sub formă de tablouri de bord și foi de lucru.
-
-
-
-
- dezvoltat de: TableAU 2013 17 mai
- scris în: JAVA, C++, Python, C
- versiunea actuală stabilă: TableAU 8.2
-
-
-
companiile care utilizează Tableau:

Plotly
![]()
folosit în principal pentru a face crearea de grafice mai rapid și mai eficient. Biblioteci API pentru Python, R, MATLAB, nod.js, Julia și Arduino și un API REST. Plotly poate fi, de asemenea, utilizat pentru a stil grafice Interactive cu Jupyter notebook.
-
-
-
-
- dezvoltat de: Plotly în anul 2012
- scris în: JavaScript
- versiunea actuală stabilă: Plotly 1.47.4
-
-
-
companiile care utilizează Plotly:
 acum să discutăm despre tehnologiile emergente de date mari
acum să discutăm despre tehnologiile emergente de date mari
tehnologii emergente de date mari
TensorFlow

TensorFlow are un ecosistem cuprinzător și flexibil de instrumente, Biblioteci și resurse comunitare, care permite cercetătorilor să împingă cele mai moderne tehnologii în învățarea automată, iar dezvoltatorii pot construi și implementa cu ușurință aplicații de învățare automată.
-
-
-
-
- dezvoltat de: echipa Google Brain în anul 2019
- scris în: Python, C++, CUDA
- versiune stabilă curentă: TensorFlow 2.0 beta
-
-
-
companii care utilizează TensorFlow:

Beam
![]()
Apache Beam oferă un strat API portabil pentru construirea de conducte sofisticate de prelucrare a datelor paralele care pot fi executate într-o diversitate de motoare de execuție sau alergători.
-
-
-
-
- dezvoltat de: Apache Software Foundation în anul 2016 15 iunie
- scris în: JAVA, Python
- curent versiune stabilă: Apache Beam 0.1.0 incubare.
-
-
-
companii care utilizează Beam:
 Docker
Docker

Docker este un instrument conceput pentru a facilita crearea, implementarea și rularea aplicațiilor utilizând containere. Containerele permit unui dezvoltator să împacheteze o aplicație cu toate părțile de care are nevoie, cum ar fi bibliotecile și alte dependențe, și să o expedieze ca un singur pachet.
-
-
-
-
- dezvoltat de: Docker INC în anul 2003 13 martie.
- scris în: Go
- versiune stabilă curentă: Docker 18.09
-
-
-
companiile care utilizează Docker:

Airflow
![]() Apache Airflow este un sistem de automatizare și planificare a fluxului de lucru care poate fi utilizat pentru a crea și gestiona conductele de date. Airflow utilizează fluxuri de lucru Realizate din grafice aciclice direcționate (dag) ale sarcinilor. Definirea fluxurilor de lucru în cod oferă întreținere, testare și versionare mai ușoare.
Apache Airflow este un sistem de automatizare și planificare a fluxului de lucru care poate fi utilizat pentru a crea și gestiona conductele de date. Airflow utilizează fluxuri de lucru Realizate din grafice aciclice direcționate (dag) ale sarcinilor. Definirea fluxurilor de lucru în cod oferă întreținere, testare și versionare mai ușoare.
-
-
-
-
- dezvoltat de: Apache Software Foundation pe 15 Mai 2019
- scris în: Python
- versiunea actuală stabilă: Apache AirFlow 1.10.3
-
-
-
companiile care utilizează AirFlow:

Kubernetes
 Kubernetes este un instrument de gestionare a clusterelor și a containerelor agnostice, deschis de Google în 2014. Oferă o platformă pentru automatizarea, implementarea, scalarea și operațiunile containerelor de aplicații în grupuri de gazde.
Kubernetes este un instrument de gestionare a clusterelor și a containerelor agnostice, deschis de Google în 2014. Oferă o platformă pentru automatizarea, implementarea, scalarea și operațiunile containerelor de aplicații în grupuri de gazde.
-
-
-
-
- dezvoltat de: Cloud Native Computing Foundation în anul 2015 21 iulie
- scris în: Go
- versiunea actuală stabilă: Kubernetes 1.14
-
-
-
companii care utilizează Kubernetes:

cu aceasta, ajungem la sfârșitul acestui articol. Sper că am aruncat o lumină asupra cunoștințelor dvs. despre Big Data și tehnologiile sale.
acum că ați înțeles Big data și tehnologiile sale, consultați instruirea Hadoop de Edureka, o companie de învățare online de încredere, cu o rețea de peste 250.000 de cursanți mulțumiți răspândiți pe tot globul. Cursul de formare de certificare Edureka Big Data Hadoop îi ajută pe cursanți să devină experți în HDFS, Fire, MapReduce, Pig, Hive, HBase, Oozie, Flume și Sqoop folosind cazuri de utilizare în timp real în domeniul comerțului cu amănuntul, Social Media, Aviație, turism, Finanțe.