KDnuggets
Av Sydney Firmin, Alteryx.
”i huvudsak är alla modeller fel, men vissa modeller är användbara.”- George Box
detta berömda George Box-citat registrerades först 1976 i tidningen ”Science and Statistics”, publicerad i Journal of the American Statistical Association. Det är ett viktigt citat till området statistik och analytiska modeller och kan packas upp i två delar.
alla modeller har fel
för att gräva i detta uttalande måste vi definiera och undersöka vad en modell är.
för sammanhanget i denna artikel kan en modell betraktas som en förenklad representation av ett system eller objekt. Statistiska modeller approximerar mönster i en datamängd genom att göra antaganden om data såväl som den miljö den samlades in och tillämpades på.
de tre breda kategorierna av antaganden som görs av statistiska modeller är fördelningsantaganden (antaganden om fördelningen av värden i en variabel eller fördelningen av observationsfel), strukturella antaganden (antaganden om det funktionella förhållandet mellan variabler) och antaganden om korsvariationer (gemensam sannolikhetsfördelning).
till exempel antar en linjär regressionsmodell att relationerna mellan variabler i en datamängd är linjära (och endast linjära). I ögonen på en linjär modell är varje avstånd mellan observationerna som utgör datamängden och den modellerade linjen bara brus (dvs. slumpmässiga eller oförklarliga fluktuationer i data) och kan i slutändan ignoreras.
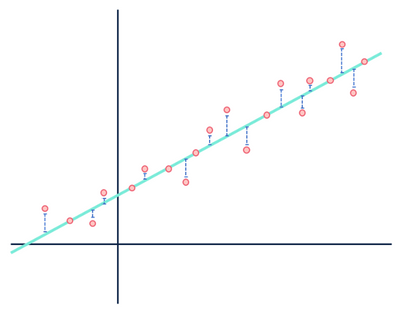
bry dig inte om avstånden i blått.
George Box uppgav att alla modeller är fel specifikt i samband med statistiska modeller. Eftersom själva karaktären av en modell är en förenklad och idealiserad representation av något, kommer alla modeller att vara fel på något sätt. Modeller kommer aldrig att vara ”sanningen” om sanningen betyder helt representativ för verkligheten. Det är mycket viktigt att överväga de antaganden som gjorts för att generera en modell eftersom modeller bara är till stor hjälp när antagandena hålls uppe.
kartor och miniatyrer
liknande observationer till Box ”alla modeller är fel” finns i många olika områden.
det finns en aforism som refererar till förhållandet mellan karta och territorium, tillskrivet Alfred Korzybski:
en karta är inte det territorium den representerar, men om den är korrekt har den en liknande struktur som territoriet, som står för dess användbarhet.
kartor är användbara eftersom de är abstraktioner av ett verkligt objekt i en mer hanterbar skala, men de kommer alltid att utesluta en viss detaljnivå. Beroende på hur mycket område en karta innehåller kan det också finnas viss snedvridning på grund av kartans projektion (orsakad av den knepiga processen att omvandla en sfärisk jordklot till en platt representation).
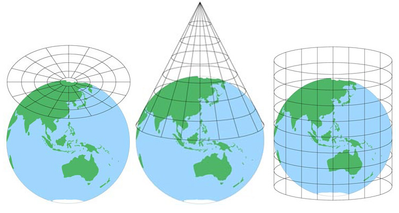
(Bildkälla.)
den enda riktigt exakta kartan skulle vara en 1:1-replikering av det territorium det representerar. En sådan karta skulle dock inte vara mer användbar än att navigera i själva territoriet.
Tänk på citatet från poeten Paul Valery:
allt enkelt är falskt. Allt som är komplext är oanvändbart.
uppkallad efter en Stanford business professor, boninis Paradox beskriver utmaningen att skapa användbara, kompletta modeller eller simuleringar av komplexa system. Det finns ofta en balans mellan komplexitet och noggrannhet i modellutvecklingen. Om målet med en modell är att göra en relation eller ett system tydligare, ökar komplexiteten det syftet (även om det kan göra modellen mer exakt).
på en hög nivå beskriver map-territory-förhållandet också förhållandet mellan ett objekt och en representation av objektet.
om du någonsin har tagit en filosofiklass kan du ha stött på verket the Treachery of Images av den surrealistiska konstnären Rene Magritte.

texten översätts till ” detta är inte ett rör.”Och det är det inte. Vi kan inte fylla den här (digitala) bilden med tobak och röka den eftersom det bara är en representation av ett verkligt objekt.
modeller är abstraktioner. Liksom kartor, miniatyrarkitektoniska modeller eller scheman kan de inte fånga alla detaljer i objektet eller systemet de bygger på, om bara för att de inte existerar i den verkliga världen och inte fungerar på samma sätt.

Om Alla Modeller Är Fel, Varför Bry Sig?
George boxas aforism är inte utan dess kritiker.
problemet som många statistiker har med detta citat verkar i stort sett falla i två kategorier:
- modeller som har fel är ett uppenbart uttalande. Naturligtvis är alla modeller fel, de är modeller.
- detta citat används som en ursäkt för dåliga modeller.
statistiker J. Michael Steele har varit kritisk till ordspråket (se denna personliga uppsats). Steeles främsta argument är att ”fel” bara spelar in om modellen inte korrekt svarar på den fråga som den hävdar att svara på (t. ex., att en byggnad på en karta är felmärkt, inte att byggnaden representeras av en liten torg). Steele fortsätter till staten:
majoriteten av publicerade statistiska metoder hungrar efter ett ärligt exempel.
Steele hävdar att statistiska modeller ofta inte är upp till en adekvat träningsåtgärd, och många modeller som utvecklats av statistiker är inte tillräckliga för deras avsedda användningsfall.
i artikeln statistik som en vetenskap, inte en konst: Sättet att överleva i datavetenskap, Mark van der Laan (statistik vid UC Berkeley) attribut rutan citat som en bidragande orsak till dåliga statistiska modeller och avfärdar det som ”fullständigt nonsens.”Han fortsätter att skriva:
grunden för statistik ( … ) kunde inte ha varit att godtyckligt välja en ”bekväm” statistisk modell. Men det är precis vad de flesta statistiker gör glatt, med stolt hänvisning till citatet, ”Alla modeller är fel, men vissa är användbara.”På grund av detta är modeller som är så orealistiska att de indexeras av en ändlig dimensionell parameter fortfarande status quo, även om alla är överens om att de är kända för att vara falska.
som en lösning kallar Van der Laan statistiker att sluta använda Box citat och göra ett åtagande att ta data, statistik och den vetenskapliga metoden på allvar. Han uppmanar statistiker att spendera tid på att lära sig hur data i en given datamängd genererades och förbinda sig att utveckla realistiska statistiska modeller med hjälp av maskininlärning och dataadaptiva uppskattningstekniker över mer traditionella parametriska modeller.
denna artikel har svar från statistiker Michael Lavine och Christopher Tong, samt ett svar på svaren från den ursprungliga författaren. De två vederlägga statistiker pekar på exempel där modeller är kända för att vara fel men används ofta eftersom de är användbara, och passar för ett givet problem. Deras exempel inkluderar de tre olika modellerna av ljus som finns inom optikområdet (geometrisk optik, fysisk optikoch kvantoptik; alla tre modellerna representerar ljus annorlunda, är ”fel” på något sätt och används fortfarande idag) och det (nästan) linjära förhållandet mellan kolflödesloggen och marktemperaturen som finns i data som samlats in i Harvard Forest.
i sin tur svarar Van der Laan på dessa exempel och andra kritik av sin artikel, särskilt hans koncept att hitta en ”sann” modell. Svarsbreven är definitivt värda en läsning om du är intresserad. Detta utgör ett aktivt debattområde inom statistik och datavetenskap.
men vissa modeller är användbara
trots modellernas begränsningar kan många modeller vara mycket användbara. Eftersom de förenklas är modeller ofta användbara för att förstå en viss komponent eller fasett i ett system.
i samband med datavetenskap kan maskininlärning och statistiska modeller vara användbara för att uppskatta (förutsäga) okända värden. I många sammanhang, om modellens antaganden håller, kan en osäker uppskattning från en stark statistisk modell fortfarande vara till stor hjälp för att fatta beslut.
den andra, mindre citerade hälften av George Box visdom är detta:
”den praktiska frågan är hur fel (modeller) måste vara för att inte vara användbara.”- George Box
Låt oss ta en titt på vårt linjära regressionsexempel:
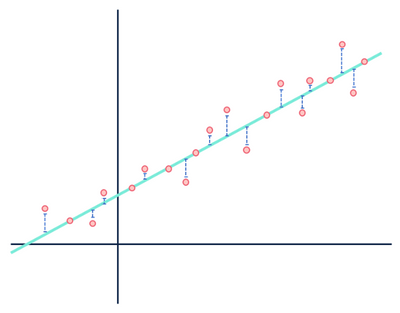
för det mesta spenderade jag för mycket tid på den här bilden för att använda den bara en gång.
Låt oss nu titta på en annan teoretisk linjär regressionsmodell som passar till en annan datamängd.
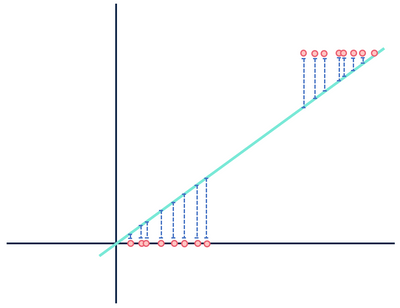
bry dig inte om avstånden… vänta det här kan inte vara rätt.
båda siffrorna visar fel, men en datamängd visar ett tydligt linjärt förhållande medan den andra är logistisk. Båda modellerna är” fel”, men man fångar tydligt ett verkligt förhållande mellan variabler, medan den andra inte gör det, vilket gör en användbar och en värdelös. Att kassera avstånden i blått som brus är rimligt om data har ett linjärt förhållande, men detta antagande faller isär när förhållandet har en annan funktionell form än din valda modell.
göra bra modeller
det faktum att modeller är felaktiga eller begränsade inom ramen för vad de representerar kan tyckas uppenbart för många som arbetar med modeller, men tyvärr inser många inte det eller tänker på det mycket. Det är därför jag anser att det är viktigt att hålla George Box ord i åtanke när man utvecklar en modell. Det ska inte användas som en ursäkt för att bygga dåliga modeller.
för vidare läsning har Steele några bra klassanteckningar: är modellen meningsfull? och är modellen meningsfull? Del II: utnyttjande av tillräcklighet. En annan stor resurs är papperet’ alla modeller har fel…’: En introduktion till modellosäkerhet från en modellvalsverkstad som hölls 2011 i Groningen.
en annan intressant läsning är när alla modeller har fel från frågor inom vetenskap och teknik, som uppmanar Box ord som en uppmaning till strängare öppenhet i vetenskapliga och statistiska modeller.
det viktiga att ta bort från allt detta är att se till att du förstår vilka aspekter av dina data som fångas av din modell och vilka aspekter som inte är. Det är viktigt att kontrollera dina antaganden och utgångspunkter. Som statistiker eller datavetare är det ditt ansvar att producera rigorösa modeller samt känna till deras begränsningar. Rapportera alltid din osäkerhet såväl som omfattningen av din modell. Med det i åtanke kommer du att kunna göra modeller som, även om de är felaktiga, säkert kan vara användbara.
Original. Reposted med tillstånd.
Bio: En geograf genom utbildning och en data nörd i hjärtat, Sydney tror starkt att data och kunskap är mest värdefulla när de tydligt kan kommuniceras och förstås. I sin nuvarande roll som Sr.Data Science content Engineer får hon spendera sina dagar på att göra det hon älskar bäst; omvandla teknisk kunskap och forskning till engagerande, kreativt och roligt innehåll för Alteryx-samhället.
relaterat:
- de 3 största misstagen på att lära sig datavetenskap
- 3 stora problem med Big Data och hur man löser dem
- välja mellan Modellkandidater