Top store datateknologier, som du har brug for at vide
store datateknologier, det brummer-ord, som du får høre meget i de seneste dage. I denne artikel, vi skal diskutere de banebrydende teknologier, der fik Big Data til at sprede sine grene for at nå større højder.
- Hvad er Big Data teknologi?
- typer af Big Data teknologi
- Top Big Data teknologier
- Emerging Big Data teknologier
Hvad er Big Data teknologi?
Big Data Technology kan defineres som et program-værktøj, der er designet til at analysere, behandle og udtrække oplysninger fra en ekstremt kompleks og store datasæt, som den traditionelle databehandling programmel aldrig kunne beskæftige sig med.

vi har brug for store Databehandlingsteknologier til at analysere denne enorme mængde realtidsdata og komme med konklusioner og forudsigelser for at reducere risiciene i fremtiden.
lad os nu se på de kategorier, hvor Big Data-teknologierne er klassificeret:
typer af Big Data teknologier:
Big Data teknologi er hovedsageligt klassificeret i to typer:
- operationelle Big Data teknologier
- analytiske Big Data teknologier

for det første handler de operationelle Big Data om de normale daglige data, som vi genererer. Dette kan være onlinetransaktioner, sociale medier eller data fra en bestemt Organisation osv. Du kan endda betragte dette som en slags rådata, der bruges til at fodre de analytiske Big Data-teknologier.
et par eksempler på operationelle Big Data-teknologier er som følger:
- online billetbestillinger, som inkluderer dine togbilletter, flybilletter, filmbilletter osv.
- Online shopping, som er din
, Flipkart, Snap deal og mange flere. - Data fra sociale medier som Facebook, Instagram, Hvad er app og meget mere.
- medarbejderoplysningerne for ethvert multinationalt selskab.
så lad os med dette gå ind i de analytiske Big Data-teknologier.
analytisk Big Data er som den avancerede version af Big Data-teknologier. Det er lidt kompliceret end de operationelle Big Data. Kort sagt, analytisk big data er, hvor den faktiske præstationsdel kommer ind i billedet, og de afgørende forretningsbeslutninger i realtid træffes ved at analysere de operationelle Big Data.
få eksempler på analytiske Big Data teknologier er som følger:

- Stock marketing
- udførelse af rummissioner, hvor hver eneste smule information er afgørende.
- vejrudsigt oplysninger.
- medicinske områder, hvor en bestemt patients sundhedsstatus kan overvåges.
lad os se på de bedste Big Data-teknologier, der bruges i IT-branchen.
Top Big Data Technologies
Top big data technologies er opdelt i 4 felter, der er klassificeret som følger:
- datalagring
- Data Mining
- dataanalyse
- datavisualisering
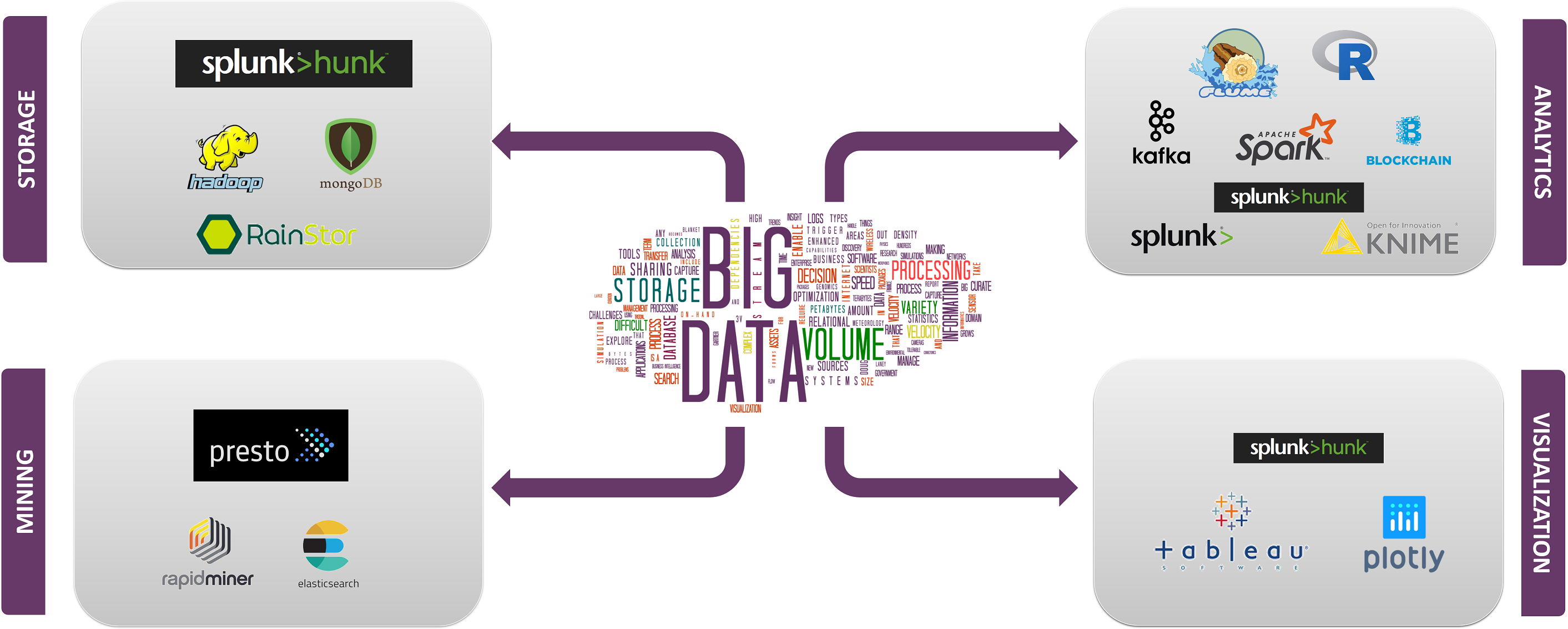
lad os nu behandle de teknologier, der falder ind under hver af disse kategorier, med deres fakta og evner sammen med de virksomheder, der bruger dem.
lad os komme i gang med Big Data teknologier i datalagring.
datalagring
Hadoop
![]()
Hadoop-rammen blev designet til at gemme og behandle data i et distribueret Databehandlingsmiljø med råvareudstyr med en simpel programmeringsmodel. Det kan gemme og analysere data til stede i forskellige maskiner med høje hastigheder og lave omkostninger.
-
-
-
-
- udviklet af: Apache Foundation i år 2011 10.December.
- skrevet i: JAVA
- nuværende stabile version: Hadoop 3.11
-
-
-
virksomheder, der bruger Hadoop:
MongoDB

MongoDB, tilbyder et direkte alternativ til det stive skema, der bruges i relationsdatabaser. Dette gør det muligt for MongoDB at tilbyde fleksibilitet, mens man håndterer en lang række datatyper i store mængder og på tværs af distribuerede arkitekturer.
-
-
-
-
- udviklet af: MongoDB i år 2009 11 Feb
- skrevet i: C++, Go, JavaScript, Python
- nuværende stabile version: MongoDB 4.0.10
-
-
-
virksomheder, der bruger MongoDB:

Rainstor
![]() RainStor er et programfirma, der udviklede et databasestyringssystem med samme navn designet til at styre og analysere Big Data for store virksomheder. Det bruger Deduplikeringsteknikker til at organisere processen med lagring af store mængder data til reference.
RainStor er et programfirma, der udviklede et databasestyringssystem med samme navn designet til at styre og analysere Big Data for store virksomheder. Det bruger Deduplikeringsteknikker til at organisere processen med lagring af store mængder data til reference.
-
-
-
-
- udviklet af RainStor i 2004.
- fungerer som: KVL
- nuværende stabil version: RainStor 5.5
-
-
-
virksomheder, der bruger RainStor:

Hunk

Hunk giver dig adgang til data i fjerntliggende Hadoop-klynger gennem virtuelle indekser og giver dig mulighed for at bruge Splunk-Søgebehandlingssproget til at analysere dine data. Med Hunk kan du rapportere og visualisere store mængder fra dine Hadoop-og Noskl-datakilder.
-
-
-
-
- udviklet af: Splunk INC i år 2013.
- skrevet i: JAVA
- nuværende stabil version: Splunk Hunk 6.2
-
-
-
lad os nu flytte ind i Big Data teknologier, der anvendes i Data Mining.
Data Mining
Presto

Presto er en open source distribueret FORESPØRGSELSMOTOR til at køre interaktive analytiske forespørgsler mod datakilder i alle størrelser lige fra Gigabyte til petabyte. Presto tillader forespørge data i Hive, Cassandra, relationelle databaser og proprietære datalagre.
-
-
-
-
- udviklet af: Apache Foundation i år 2013.
- skrevet i: JAVA
- nuværende stabil version: Presto 0.22
-
-
-
virksomheder, der bruger Presto:

Rapid Miner
![]()
RapidMiner er en centraliseret løsning, der har en meget kraftfuld og robust grafisk brugergrænseflade, der giver brugerne mulighed for at oprette, levere og vedligeholde forudsigelig analyse. Det giver mulighed for at skabe meget avancerede arbejdsgange, Scripting support på flere sprog.
-
-
-
-
- udviklet af: RapidMiner i år 2001
- skrevet i: JAVA
- nuværende stabil version: RapidMiner 9.2
-
-
-
virksomheder, der bruger RapidMiner:

Elasticsearch
![]()
Elasticsearch er en søgemaskine baseret på Lucene biblioteket. Det giver en distribueret, MultiTenant-kapabel, Fuldtekstsøgemaskine med en HTTP-grænseflade og Skemafrie JSON-dokumenter.
-
-
-
-
- udviklet af: Elastisk NV i år 2012.
- skrevet i: JAVA
- nuværende stabil version: ElasticSearch 7.1
-
-
-
virksomheder, der bruger Elasticsearch:

med dette kan vi nu flytte ind i Big Data-teknologier, der bruges i dataanalyse.
dataanalyse
Kafka

Apache Kafka er en distribueret Streaming platform. En streamingplatform har tre nøglefunktioner, der er som følger:
-
-
-
-
- udgiver
- abonnent
- forbruger
-
-
-
dette svarer til en Meddelelseskø eller et Enterprise-meddelelsessystem.
- udviklet af: Apache Foundation i år 2011
- skrevet i: Scala, JAVA
- nuværende stabile version: Apache Kafka 2.2.0
virksomheder, der bruger Kafka:

Splunk
 Splunk indfanger, indekserer og korrelerer realtidsdata i et søgbart arkiv, hvorfra det kan generere grafer, rapporter, advarsler, Dashboards og datavisualiseringer. Det bruges også til applikationsstyring, sikkerhed og overholdelse samt forretnings-og Internetanalyse.
Splunk indfanger, indekserer og korrelerer realtidsdata i et søgbart arkiv, hvorfra det kan generere grafer, rapporter, advarsler, Dashboards og datavisualiseringer. Det bruges også til applikationsstyring, sikkerhed og overholdelse samt forretnings-og Internetanalyse.
-
-
-
-
- udviklet af: Splunk INC i år 2014 6 maj
- skrevet i: ajaks, C++, Python,
- nuværende stabil version: Splunk 7.3
-
-
-
virksomheder, der bruger Splunk:

KNIME
 KNIME giver brugerne mulighed for visuelt at oprette datastrømme, selektivt udføre nogle eller alle Analysetrin og inspicere resultater, modeller og interaktive visninger. KNIME er skrevet i Java og baseret på Eclipse og gør brug af sin Udvidelsesmekanisme til at tilføje Plugins, der giver yderligere funktionalitet.
KNIME giver brugerne mulighed for visuelt at oprette datastrømme, selektivt udføre nogle eller alle Analysetrin og inspicere resultater, modeller og interaktive visninger. KNIME er skrevet i Java og baseret på Eclipse og gør brug af sin Udvidelsesmekanisme til at tilføje Plugins, der giver yderligere funktionalitet.
-
-
-
-
- udviklet af: KNIME i år 2008
- skrevet i: JAVA
- nuværende stabil version: KNIME 3.7.2
-
-
-
virksomheder, der bruger KNIME:
 Spark
Spark

Spark leverer computerfunktioner i hukommelsen til at levere hastighed, en generaliseret Eksekveringsmodel, der understøtter en lang række applikationer, og Java, Scala og Python API ‘ er for at lette udviklingen.
-
-
-
-
- udviklet af: Apache Foundation
- skrevet i: Java, Scala, Python, R
- nuværende stabil version: Apache Spark 2.4.3
-
-
-
virksomheder, der bruger Spark:

R-sprog

R er et programmeringssprog og et frit programmelmiljø til statistisk databehandling og grafik. R-sproget er meget udbredt blandt statistikere og data minearbejdere til udvikling af statistiske programmer og hovedsagelig i dataanalyse.
-
-
-
-
- udviklet af: R-Foundation i år 2000 29 Feb
- skrevet i: Fortran
- nuværende stabil version: R-3.6.0
-
-
-
virksomheder, der bruger R-Language:

Blockchain
![]() BlockChain bruges i væsentlige funktioner såsom betaling, deponering og titel kan også reducere svig, øge det økonomiske privatliv, fremskynde transaktioner og internationalisere markeder.
BlockChain bruges i væsentlige funktioner såsom betaling, deponering og titel kan også reducere svig, øge det økonomiske privatliv, fremskynde transaktioner og internationalisere markeder.
BlockChain kan bruges til at opnå følgende i et Forretningsnetværksmiljø:
-
-
-
-
- delt hovedbog: Her kan vi tilføje det distribuerede system af poster på tværs af et forretningsnetværk.
- Smart kontrakt: Forretningsbetingelser er indlejret i transaktionsdatabasen og udføres med transaktioner.
- privatliv: sikring af passende synlighed, transaktioner er sikre, autentificerede og verificerbare
- konsensus: alle parter i et forretningsnetværk accepterer netværksbekræftede transaktioner.
-
-
-
- udviklet af: Bitcoin
- skrevet i: JavaScript, C++, Python
- nuværende stabil version: Blockchain 4.0
virksomheder, der bruger Blockchain:

med dette skal vi flytte ind i datavisualisering store datateknologier
datavisualisering
Tableau

Tableau er et kraftfuldt og hurtigst voksende Datavisualiseringsværktøj, der bruges i Business Intelligence-branchen. Dataanalyse er meget hurtig med Tableau, og de visualiseringer, der oprettes, er i form af Dashboards og regneark.
-
-
-
-
- udviklet af: TableAU 2013 17 maj
- skrevet i: JAVA, C++, Python, C
- nuværende stabil version: TableAU 8.2
-
-
-
virksomheder, der bruger Tableau:

Plotly
![]()
bruges hovedsageligt til at skabe grafer hurtigere og mere effektiv. API biblioteker til Python, R, MATLAB, Node.js, Julia og Arduino og en REST API. Plotly kan også bruges til at style interaktive grafer med Jupyter notebook.
-
-
-
-
- udviklet af: Plotly i år 2012
- skrevet i: JavaScript
- nuværende stabil version: Plotly 1.47.4
-
-
-
virksomheder, der bruger Plotly:
 lad os nu diskutere de nye store datateknologier
lad os nu diskutere de nye store datateknologier
nye store datateknologier
Tensorstrøm

Tensorstrøm har et omfattende, fleksibelt økosystem af værktøjer, Biblioteker og samfundsressourcer, der lader forskere skubbe den nyeste teknologi inden for maskinlæring, og udviklere kan nemt opbygge og implementere maskinlæringsdrevne applikationer.
-
-
-
-
- udviklet af: Google Brain Team i år 2019
- skrevet i: Python, C++, CUDA
- nuværende stabil version: Tensorstrøm 2.0 beta
-
-
-
virksomheder, der bruger Tensorstrøm:

Beam
![]()
Apache Beam giver et bærbart API-lag til opbygning af sofistikerede parallelle Databehandlingsrørledninger, der kan udføres på tværs af en række Eksekveringsmotorer eller løbere.
-
-
-
-
- udviklet af: 2016 juni 15th
- skrevet i: JAVA, Python
- nuværende stabil version: Apache Beam 0.1.0 inkubering.
-
-
-
virksomheder, der bruger Beam:
 Docker
Docker

Docker er et værktøj designet til at gøre det lettere at oprette, implementere og køre applikationer ved hjælp af containere. Containere giver en udvikler mulighed for at pakke en applikation sammen med alle de dele, den har brug for, såsom biblioteker og andre afhængigheder, og sende det hele ud som en pakke.
-
-
-
-
- udviklet af: Docker INC i år 2003 13. Marts.
- skrevet i: gå
- nuværende stabile version: Docker 18.09
-
-
-
virksomheder, der bruger Docker:

luftstrøm
![]() Apache luftstrøm er en arbejdsgang automatisering og planlægning System, der kan bruges til at forfatter og administrere Data rørledninger. Luftstrøm bruger arbejdsgange lavet af rettede acykliske grafer (dag ‘ er) af opgaver. Definition af arbejdsgange i kode giver lettere vedligeholdelse, test og versionsstyring.
Apache luftstrøm er en arbejdsgang automatisering og planlægning System, der kan bruges til at forfatter og administrere Data rørledninger. Luftstrøm bruger arbejdsgange lavet af rettede acykliske grafer (dag ‘ er) af opgaver. Definition af arbejdsgange i kode giver lettere vedligeholdelse, test og versionsstyring.
-
-
-
-
- udviklet af: Apache Foundation den 15. maj 2019
- skrevet i: Python
- nuværende stabile version: Apache luftstrøm 1.10.3
-
-
-
virksomheder, der bruger luftstrøm:

Kubernetes
 Kubernetes er et leverandør-agnostisk klynge-og Containerstyringsværktøj, der blev åbnet af Google i 2014. Det giver en platform til automatisering, implementering, skalering og drift af Applikationscontainere på tværs af klynger af værter.
Kubernetes er et leverandør-agnostisk klynge-og Containerstyringsværktøj, der blev åbnet af Google i 2014. Det giver en platform til automatisering, implementering, skalering og drift af Applikationscontainere på tværs af klynger af værter.
-
-
-
-
- udviklet af: Cloud Native Computing Foundation i år 2015 21 juli
- skrevet i: Go
- nuværende stabil version: Kubernetes 1.14
-
-
-
virksomheder, der bruger Kubernetes:

med dette kommer vi til en ende af denne artikel. Jeg håber, jeg har kastet lys over din viden om Big Data og dens teknologier.
nu hvor du har forstået Big data og dens teknologier, så tjek Hadoop training af Edureka, et betroet online læringsfirma med et netværk af mere end 250.000 tilfredse elever spredt over hele kloden. Edureka Big Data Hadoop Certification Training course hjælper eleverne med at blive ekspert i HDFS, garn, MapReduce, Pig, Hive, HBase, Flume og Kvoop ved hjælp af brugssager i realtid på detailhandel, sociale medier, luftfart, turisme, økonomi domæne.